


Published on Feb 26, 2016
Updated on Feb 20, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.
Automated compliance and control for global regulations.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(41)
Insurtech(67)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(25)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(154)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(24)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
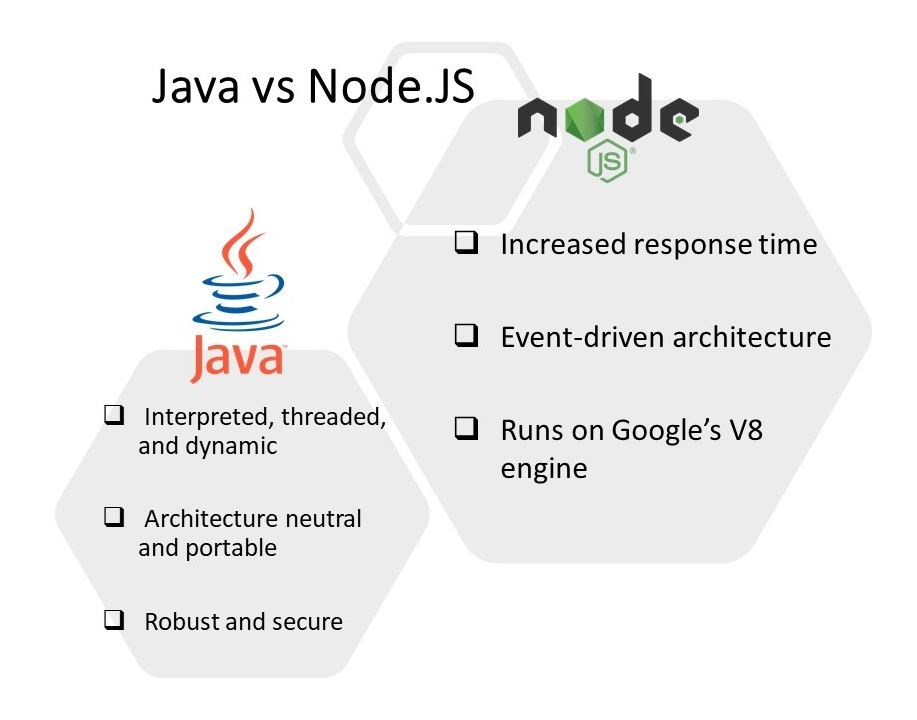
Java is considered as the best application development language. It is an object-oriented programming language which is used to create efficient quality applications for both computers and mobile phones. Java dominates Android phones, enterprise computing, and some embedded worlds like Blu-ray disks. While on the other hand Node.JS is a programming platform that allows you to write JavaScript on both the client side and the server side, mostly server-side code that is identical in syntax to browser JavaScript.
It opens up new perspectives, still having its “browser” nature. The developers use both the languages to develop applications depending on the preference and the need of application. Let’s dive into Java vs Node.JS comparison to understand the two technologies better.
With Node.js, JavaScript finds a home on the server and in the browser. The code you write for one will more than likely run the same way on both. It’s much easier to stick with JavaScript for both sides of the client/server divide than it is to write something once in Java and again in JavaScript, which you would likely need to do if you decided to move business logic you wrote in Java for the server to the browser or insisted that the logic you built for the browser be moved to the server. In either direction, Node.js and JavaScript make it much easier to migrate code.
Java developers have Eclipse, NetBeans, or IntelliJ, three top-notch tools that integrate well with debuggers, decompilers, and servers. Each has years of development, dedicated users, and solid ecosystems filled with plug-ins.
Meanwhile, most Node.js developers type words into the command line and code into their favorite text editor. Some use Eclipse or Visual Studio, both of which support Node.js. Of course, the surge of interest in Node.js means new tools are arriving, some of which, like IBM’s Node-RED offer intriguing approaches, but they’re still a long way from being as complete as Eclipse. WebStorm, for instance, is a solid commercial tool from JetBrains, linking in many command-line build tools.
Of course, if you’re looking for an IDE that edits and juggles tools, the new tools that support Node.js are good enough. But if you ask your IDE to let you edit while you operate on the running source code like a heart surgeon slice open a chest, well, Java tools are much more powerful. It’s all there, and it’s all local.
Complicated build tools like Ant and Maven have revolutionized Java programming. But there’s only one issue. You write the specification in XML, a data format that wasn’t designed to support programming logic. Sure, it’s relatively easy to express branching with nested tags, but there’s still something annoying about switching gears from Java to XML merely to build something.
Java boasts incredible tools for monitoring clusters of machines. There are deep hooks into the JVM and elaborate profiling tools to help identify bottlenecks and failures. The Java enterprise stack runs some of the most sophisticated servers on the planet, and the companies that use those servers have demanded the very best in telemetry. All of these monitoring and debugging tools are quite mature and ready for you to deploy.
There is a huge collection of libraries available in Java, and they offer some of the more serious work around. Text indexing tools like Lucene and computer vision toolkits like OpenCV are two examples of great open source projects that are ready to be the foundation of a serious project. There are plenty of libraries written in JavaScript and some of them are amazing, but the depth and quality of the Java code base is superior.
When databases spit out the answers, Java goes to elaborate lengths to turn the results into Java objects. Developers will argue for hours about POJO mappings, Hibernate, and other tools. Configuring them can take hours or even days. Eventually, the Java code gets Java objects after all of the conversions.
Many Web services and databases return data in JSON, a natural part of JavaScript. The format is now so common and useful that many Java developers use the JSON formats, so a number of good JSON parsers are available as Java libraries as well. But JSON is part of the foundation of JavaScript. You don’t need libraries. It’s all there and ready to go.
It’s a bit hard to quantify, but many of the complex packages for serious scientific work are written in Java because Java has strong mathematical foundations. Sun spent a long time sweating the details of the utility classes and it shows. There are BigIntegers, elaborate IO routines, and complex Date code with implementations of both Gregorian and Julian calendars.
JavaScript is fine for simple tasks, but there’s plenty of confusion in the guts. One easy way to see this is in JavaScript’s three different results for functions that don’t have answers: undefined, NaN, and null. Which is right? Well, each has its role — one of which is to drive programmers nuts trying to keep them straight. Issues about the weirder corners of the language rarely cause problems for simple form work, but they don’t feel like a good foundation for complex mathematical and type work.

Fast code is great, but it’s usually more important that it be correct. Here is where Java’s extra features make sense.
Java’s Web servers are multi-threaded. Creating multiple threads may take time and memory, but it pays off. If one thread deadlocks, the others continue. If one thread requires longer computation, the other threads aren’t starved for attention (usually).
However, even if one Node.js request runs too slowly, everything slows down. There’s only one thread in Node.js, and it will get to your event when it’s good and ready. It may look super fast, but underneath it uses the same architecture as a one-window post office in the week before Christmas.
There have been decades of work devoted to building smart operating systems that can juggle many different processes at the same time. Why go back in time to the ’60s when computers could handle only one thread?
Yes, all of our grandparents’ lessons about thrift are true. Waste not; want not. It can be painful to watch Silicon Valley’s foolish devotion to the “new” and “disruptive,” but sometimes cleaning out the craft makes the most sense. Yes, Java can keep up, but there’s old code everywhere. Sure, Java has new IO routines, but it also has old IO routines. Plenty of applet and until classes can get in the way.
On one side are the deep foundations of solid engineering and architecture. On the other side are simplicity and ubiquity. Will the old-school compiler-driven world of Java hold its ground, or will the speed and flexibility of Node.js help JavaScript continue to gobble up everything in its path?
I hope this article helped you understand Java vs Node.JS from developers’ perspectives. For futher queries and doubts, feel free to drop a word at hello@mantralabsglobal.com.
Related Articles-
Java dominates enterprise computing applications, whereas, Node.js allows you to write both client and server programs using Javascript. Considering the ease of development, Node.js is better, but from application performance and security point of view, Java is the best.
Java is faster than Node.js. Java relies on multi-thread architecture. Creating multiple threads may take time and memory, but it pays off. If one thread deadlocks, the others continue. Whereas, there is only one thread in Node.js. If one request runs too slowly, everything slows down.
Given the preferences for more UI-focused and Javascript-based applications, Node.js has the potential to replace Java. Node.js is also integral to MEAN stack, and today, the world demands more of MEAN stack developers and not full-stack ones.
Node.js and Java are two completely different technologies. Javascript is essentially a clien-side programming language. But, Node enhances its capabilities to code server-side programs in Javascript. Again, Javascript and Java are different and Javascript is not a part of the Java platform.
Knowledge thats worth delivered in your inbox
Smart Manufacturing starts with real-time visibility.
Manufacturing companies today generate data by the second through sensors, machines, ERP systems, and MES platforms. But without real-time insights, even the most advanced production lines are essentially flying blind.
Manufacturers are implementing real-time dashboards that serve as control towers for their daily operations, enabling them to shift from reactive to proactive decision-making. These tools are essential to the evolution of Smart Manufacturing, where connected systems, automation, and intelligent analytics come together to drive measurable impact.
Data is available, but what’s missing is timely action.
For many plant leaders and COOs, one challenge persists: operational data is dispersed throughout systems, delayed, or hidden in spreadsheets. And this delay turns into a liability.
Real-time dashboards help uncover critical answers:
By converting raw inputs into real-time manufacturing analytics, dashboards make operational intelligence accessible to operators, supervisors, and leadership alike, enabling teams to anticipate problems rather than react to them.
Line performance and downtime trends
Track OEE in real time and identify underperforming lines.
Predictive maintenance alerts
Utilize historical and sensor data to identify potential part failures in advance.
Inventory heat maps & reorder thresholds
Anticipate stockouts or overstocks based on dynamic reorder points.
Quality metrics linked to operator actions
Isolate shifts or procedures correlated with spikes in defects or rework.
These insights allow production teams to drive day-to-day operations in line with Smart Manufacturing principles.
Role-based dashboards
Dashboards can be configured for machine operators, shift supervisors, and plant managers, each with a tailored view of KPIs.
Embedded alerts and nudges
Real-time prompts, like “Line 4 below efficiency threshold for 15+ minutes,” reduce response times and minimize disruptions.
Cross-functional drill-downs
Teams can identify root causes more quickly because users can move from plant-wide overviews to detailed machine-level data in seconds.
Data lakehouse integration
Unified access to ERP, MES, IoT sensor, and QA systems—ensuring reliable and timely manufacturing analytics.
ETL pipelines
Real-time data ingestion from high-frequency sources with minimal latency.
Visualization tools
Custom builds using Power BI, or customized solutions designed for frontline usability and operational impact.
Mantra Labs partnered with a North American die-casting manufacturer to unify its operational data into a real-time dashboard. Fragmented data, manual reporting, delayed pricing decisions, and inconsistent data quality hindered operational efficiency and strategic decision-making.
As this case shows, real-time dashboards are not just operational tools—they’re strategic enablers.
(Learn More: Powering the Future of Metal Manufacturing with Data Engineering)
| Aspect | What You Should Know |
| 1. Why Static Reports Fall Short | Delayed insights after issues occur Disconnected systems (ERP, MES, sensors) No real-time alerts or embedded decision logic |
| 2. What Real-Time Dashboards Enable | Track OEE and downtime in real-time Predictive maintenance using sensor data Dynamic inventory heat maps Quality linked to operators |
| 3. Dashboards That Drive Action | Role-based views (operator to CEO) Embedded alerts like “Line 4 down for 15+ mins” Drilldowns from plant-level to machine-level |
| 4. What Powers These Dashboards | Unified Data Lakehouse (ERP + IoT + MES) Real-time ETL pipelines Power BI or custom dashboards built for frontline usability |
Smart Manufacturing dashboards aren’t just analytics tools—they’re productivity engines. Dashboards that deliver real-time insight empower frontline teams to make faster, better decisions—whether it’s adjusting production schedules, triggering preventive maintenance, or responding to inventory fluctuations.
Explore how Mantra Labs can help you unlock operations intelligence that’s actually usable.
Knowledge thats worth delivered in your inbox


Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
