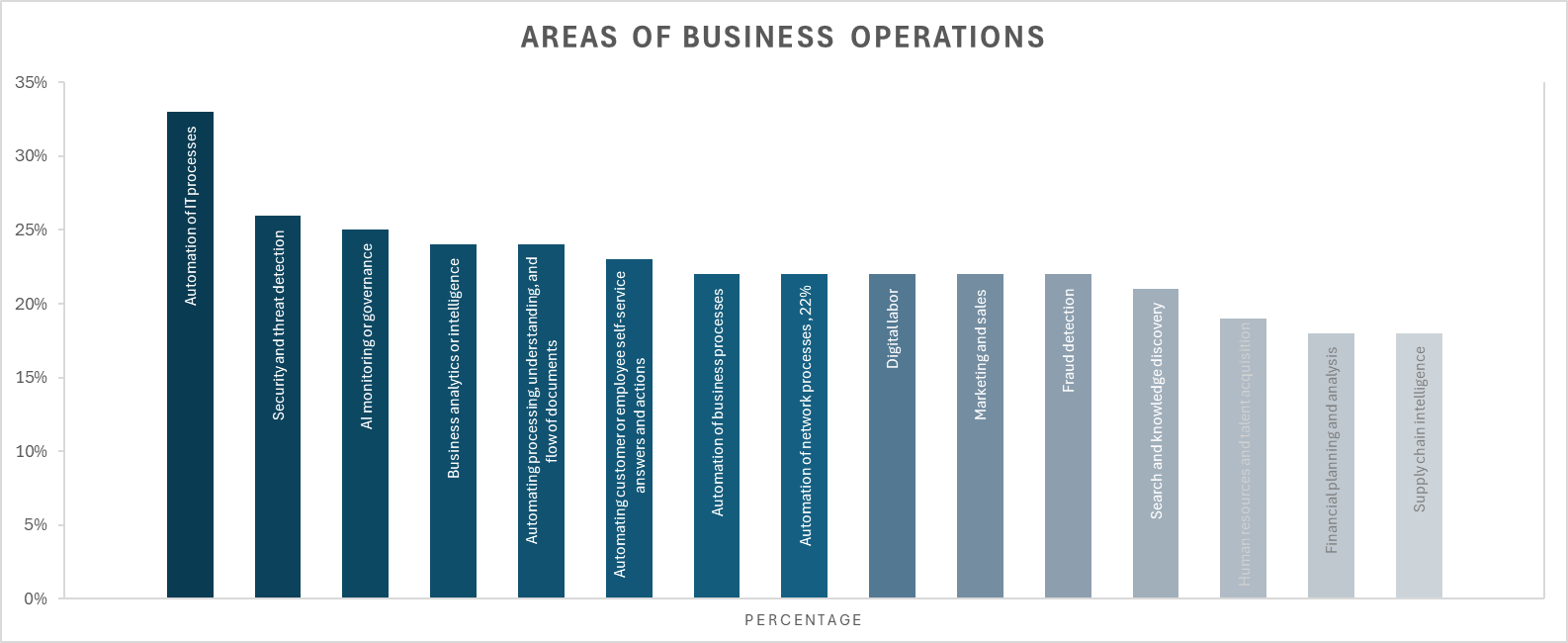
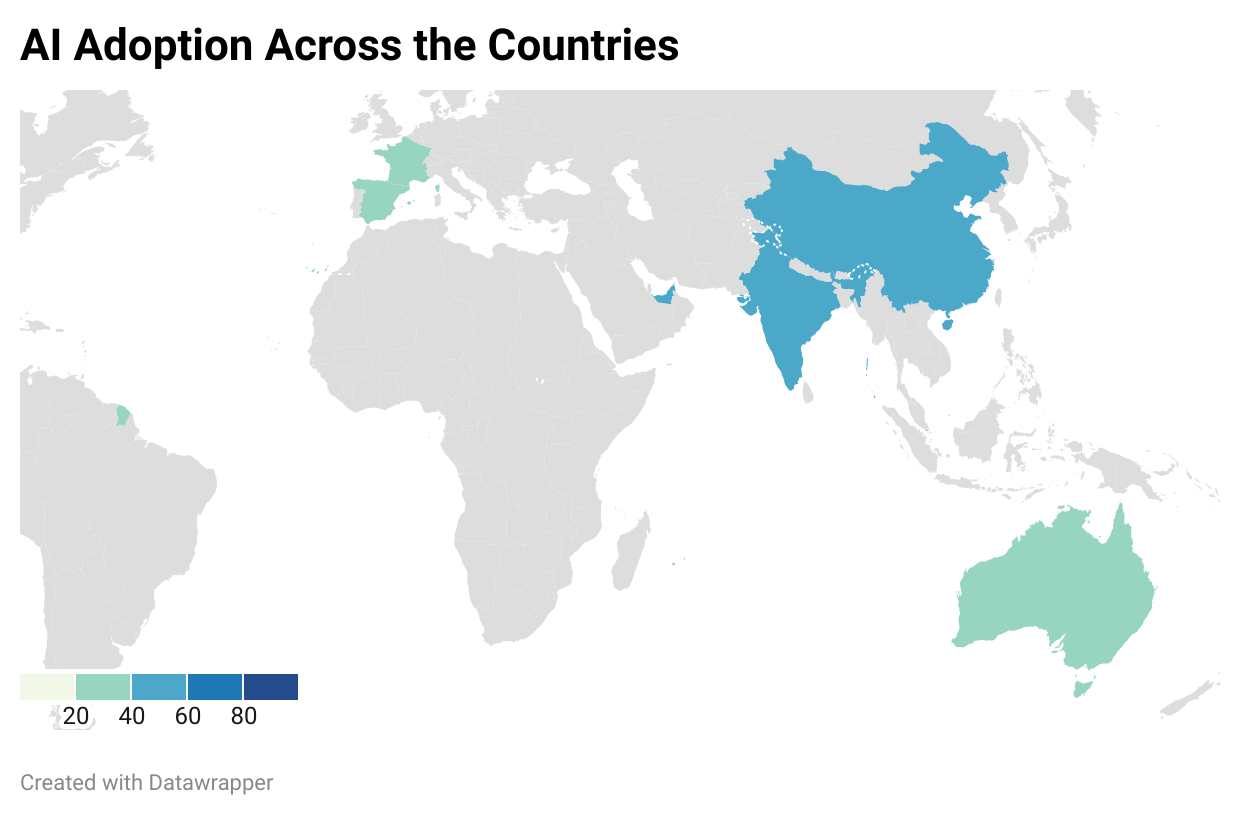
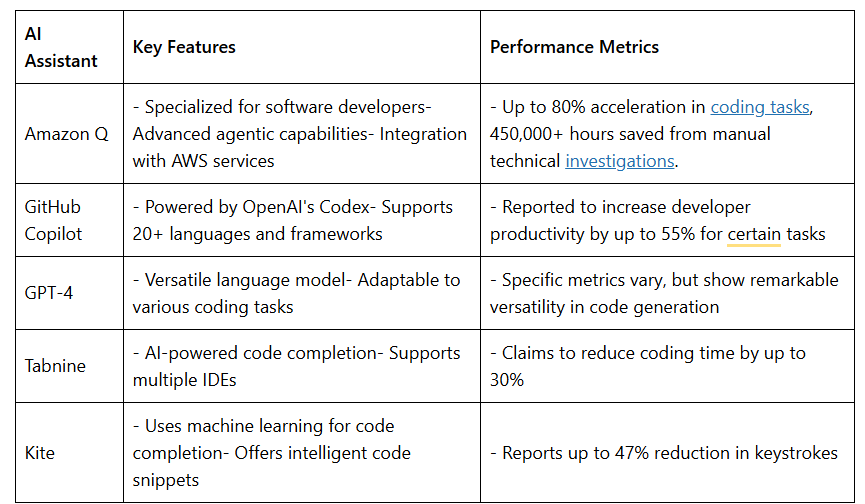
When we hear million-dollar AI mistakes, the first thought is: What could it be? Was it a massive investment in the wrong technology? Did a critical AI application go up in flames? Or was it an overhyped solution that failed to deliver on its promises? Spoiler alert: it’s often all of these—and more. From overlooked data science issues to misaligned business goals and poorly defined AI projects, failures are a mix of preventable errors.
Remember Blockbuster? They had multiple chances to embrace advanced technology like streaming but stuck to their old model, ignoring the shifting landscape. The result? Netflix became a giant while Blockbuster faded into history. AI failures follow a similar pattern—when businesses fail to adapt their processes, even the most innovative AI tools turn into liabilities. Gartner reports nearly 80% of AI projects fail, costing millions. How do companies, with all their resources and brainpower manage to bungle something as transformative as AI?
Enterprises often treat artificial intelligence as a must-have accessory rather than a strategic tool. “If our competitors have it, we need it too!” they exclaim, rushing into adoption without asking why. The result? Expensive systems that yield no measurable business outcomes. Without aligning AI’s capabilities—like natural language processing or generative AI solutions—with goals such as boosting customer experience or driving operational efficiency, AI becomes just another line item in the budget.
2. Data Woes
AI is only as smart as the data it’s fed. Yet, many enterprises underestimate the importance of clean, structured, and unbiased data. They plug in inconsistent or incomplete data and expect groundbreaking insights. The result? AI models that churn out unreliable or even harmful outcomes.
Case in Point: A faulty ATS filtered for outdated AngularJS skills, rejecting all applicants, including a manager’s fake CV. The error, unnoticed due to blind reliance on AI, cost the HR team their jobs—a stark reminder that human oversight is critical in AI systems.
3. Underestimating the Human Element
AI might be powerful, but it does not replace human judgment. Whether it’s an AI assistant like Claude AI or OpenAI’s ChatGPT API, Enterprises often overlook the need for human oversight and fail to train employees on how to interact with AI systems. What you get is either blind trust in algorithms or complete resistance from employees, both of which spell trouble.
4. Stuck in Experiment Mode
AI adoption often stagnates when businesses fixate on piloting instead of scaling. Tools like DALL-E or MidJourney may excel in proofs of concept but lack enterprise-wide integration. This leaves companies in an endless cycle of testing AI applications, wasting resources without realizing full-scale business value.
5. Ignoring Change Management
Transitioning to AI technology is as much about organizational culture as it is about deploying AI models. Mismanagement, such as overlooking ethical AI considerations or failing to explain AI’s impact on roles, leads to resistance. Whether it’s a small chatbot AI tool or full-scale AI automation, fostering employee buy-in is critical.
At Mantra Labs, we don’t just offer AI solutions—we provide a comprehensive, end-to-end strategy to help businesses adopt the complex process of AI implementation. While implementing AI can lead to transformative outcomes, it’s not a one-size-fits-all solution. True success lies in aligning the right technology with your unique business needs, and that’s where we excel. Whether you’re leveraging AI in healthcare with tools like poly AI or exploring AI trading platforms, we craft custom solutions tailored to your needs.
By addressing challenges like biased AI algorithms or misaligned AI strategies, we ensure you sidestep costly pitfalls. Our approach not only simplifies AI adoption but transforms it into a competitive advantage. Ready to avoid the million-dollar mistake and unlock AI’s full potential? Let’s make it happen—together.
AI code assistants are revolutionizing software development, with Gartner predicting that 75% of enterprise software engineers will use these tools by 2028, up from less than 10% in early 2023. This rapid adoption reflects the potential of AI to enhance coding efficiency and productivity, but also raises important questions about the maturity, benefits, and challenges of these emerging technologies.
Code Assistance Evolution
The evolution of code assistance has been rapid and transformative, progressing from simple autocomplete features to sophisticated AI-powered tools. GitHub Copilot, launched in 2021, marked a significant milestone by leveraging OpenAI’s Codex to generate entire code snippets 1. Amazon Q, introduced in 2023, further advanced the field with its deep integration into AWS services and impressive code acceptance rates of up to 50%. GPT (Generative Pre-trained Transformer) models have been instrumental in this evolution, with GPT-3 and its successors enabling more context-aware and nuanced code suggestions.
Adoption rates: By 2023, over 40% of developers reported using AI code assistants.
Productivity gains: Tools like Amazon Q have demonstrated up to 80% acceleration in coding tasks.
Language support: Modern AI assistants support dozens of programming languages, with GitHub Copilot covering over 20 languages and frameworks.
Error reduction: AI-powered code assistants have shown potential to reduce bugs by up to 30% in some studies.
These advancements have not only increased coding efficiency but also democratized software development, making it more accessible to novice programmers and non-professionals alike.
Current Adoption and Maturity: Metrics Defining the Landscape
The landscape of AI code assistants is rapidly evolving, with adoption rates and performance metrics showcasing their growing maturity. Here’s a tabular comparison of some popular AI coding tools, including Amazon Q:
Amazon Q stands out with its specialized capabilities for software developers and deep integration with AWS services. It offers a range of features designed to streamline development processes:
Highest reported code acceptance rates: Up to 50% for multi-line code suggestions
Built-in security: Secure and private by design, with robust data security measures
Extensive connectivity: Over 50 built-in, managed, and secure data connectors
Task automation: Amazon Q Apps allow users to create generative AI-powered apps for streamlining tasks
The tool’s impact is evident in its adoption and performance metrics. For instance, Amazon Q has helped save over 450,000 hours from manual technical investigations. Its integration with CloudWatch provides valuable insights into developer usage patterns and areas for improvement.
As these AI assistants continue to mature, they are increasingly becoming integral to modern software development workflows. However, it’s important to note that while these tools offer significant benefits, they should be used judiciously, with developers maintaining a critical eye on the generated code and understanding its implications for overall project architecture and security.
AI-Powered Collaborative Coding: Enhancing Team Productivity
AI code assistants are revolutionizing collaborative coding practices, offering real-time suggestions, conflict resolution, and personalized assistance to development teams. These tools integrate seamlessly with popular IDEs and version control systems, facilitating smoother teamwork and code quality improvements.
Key features of AI-enhanced collaborative coding:
Real-time code suggestions and auto-completion across team members
Automated conflict detection and resolution in merge requests
Personalized coding assistance based on individual developer styles
AI-driven code reviews and quality checks
Benefits for development teams:
Increased productivity: Teams report up to 30-50% faster code completion
Improved code consistency: AI ensures adherence to team coding standards
Reduced onboarding time: New team members can quickly adapt to project codebases
Enhanced knowledge sharing: AI suggestions expose developers to diverse coding patterns
While AI code assistants offer significant advantages, it’s crucial to maintain a balance between AI assistance and human expertise. Teams should establish guidelines for AI tool usage to ensure code quality, security, and maintainability.
Emerging trends in AI-powered collaborative coding:
Integration of natural language processing for code explanations and documentation
Advanced code refactoring suggestions based on team-wide code patterns
AI-assisted pair programming and mob programming sessions
Predictive analytics for project timelines and resource allocation
As AI continues to evolve, collaborative coding tools are expected to become more sophisticated, further streamlining team workflows and fostering innovation in software development practices.
Benefits and Risks Analyzed
AI code assistants offer significant benefits but also present notable challenges. Here’s an overview of the advantages driving adoption and the critical downsides:
Core Advantages Driving Adoption:
Enhanced Productivity: AI coding tools can boost developer productivity by 30-50%1. Google AI researchers estimate that these tools could save developers up to 30% of their coding time.
Industry
Potential Annual Value
Banking
$200 billion – $340 billion
Retail and CPG
$400 billion – $660 billion
Economic Impact: Generative AI, including code assistants, could potentially add $2.6 trillion to $4.4 trillion annually to the global economy across various use cases. In the software engineering sector alone, this technology could deliver substantial value.
Democratization of Software Development: AI assistants enable individuals with less coding experience to build complex applications, potentially broadening the talent pool and fostering innovation.
Instant Coding Support: AI provides real-time suggestions and generates code snippets, aiding developers in their coding journey.
Critical Downsides and Risks:
Cognitive and Skill-Related Concerns:
Over-reliance on AI tools may lead to skill atrophy, especially for junior developers.
There’s a risk of developers losing the ability to write or deeply understand code independently.
Technical and Ethical Limitations:
Quality of Results: AI-generated code may contain hidden issues, leading to bugs or security vulnerabilities.
Security Risks: AI tools might introduce insecure libraries or out-of-date dependencies.
Ethical Concerns: AI algorithms lack accountability for errors and may reinforce harmful stereotypes or promote misinformation.
Copyright and Licensing Issues:
AI tools heavily rely on open-source code, which may lead to unintentional use of copyrighted material or introduction of insecure libraries.
Limited Contextual Understanding:
AI-generated code may not always integrate seamlessly with the broader project context, potentially leading to fragmented code.
Bias in Training Data:
AI outputs can reflect biases present in their training data, potentially leading to non-inclusive code practices.
While AI code assistants offer significant productivity gains and economic benefits, they also present challenges that need careful consideration. Developers and organizations must balance the advantages with the potential risks, ensuring responsible use of these powerful tools.
Future of Code Automation
The future of AI code assistants is poised for significant growth and evolution, with technological advancements and changing developer attitudes shaping their trajectory towards potential ubiquity or obsolescence.
Technological Advancements on the Horizon:
Enhanced Contextual Understanding: Future AI assistants are expected to gain deeper comprehension of project structures, coding patterns, and business logic. This will enable more accurate and context-aware code suggestions, reducing the need for extensive human review.
Multi-Modal AI: Integration of natural language processing, computer vision, and code analysis will allow AI assistants to understand and generate code based on diverse inputs, including voice commands, sketches, and high-level descriptions.
Autonomous Code Generation: By 2027, we may see AI agents capable of handling entire segments of a project with minimal oversight, potentially scaffolding entire applications from natural language descriptions.
Self-Improving AI: Machine learning models that continuously learn from developer interactions and feedback will lead to increasingly accurate and personalized code suggestions over time.
Adoption Barriers and Enablers:
Barriers:
Data Privacy Concerns: Organizations remain cautious about sharing proprietary code with cloud-based AI services.
Integration Challenges: Seamless integration with existing development workflows and tools is crucial for widespread adoption.
Skill Erosion Fears: Concerns about over-reliance on AI leading to a decline in fundamental coding skills among developers.
Enablers:
Open-Source Models: The development of powerful open-source AI models may address privacy concerns and increase accessibility.
IDE Integration: Deeper integration with popular integrated development environments will streamline adoption.
Demonstrable ROI: Clear evidence of productivity gains and cost savings will drive enterprise adoption.
Future Trends in Code Automation:
AI-Driven Architecture Design: AI assistants may evolve to suggest optimal system architectures based on project requirements and best practices.
Automated Code Refactoring: AI tools will increasingly offer intelligent refactoring suggestions to improve code quality and maintainability.
Predictive Bug Detection: Advanced AI models will predict potential bugs and security vulnerabilities before they manifest in production environments.
Cross-Language Translation: AI assistants will facilitate seamless translation between programming languages, enabling easier migration and interoperability.
AI-Human Pair Programming: More sophisticated AI agents may act as virtual pair programming partners, offering real-time guidance and code reviews.
Ethical AI Coding: Future AI assistants will incorporate ethical considerations, suggesting inclusive and bias-free code practices.
As these trends unfold, the role of human developers is likely to shift towards higher-level problem-solving, creative design, and AI oversight. By 2025, it’s projected that over 70% of professional software developers will regularly collaborate with AI agents in their coding workflows1. However, the path to ubiquity will depend on addressing key challenges such as reliability, security, and maintaining a balance between AI assistance and human expertise.
The future outlook for AI code assistants is one of transformative potential, with the technology poised to become an integral part of the software development landscape. As these tools continue to evolve, they will likely reshape team structures, development methodologies, and the very nature of coding itself.
Conclusion: A Tool, Not a Panacea
AI code assistants have irrevocably altered software development, delivering measurable productivity gains but introducing new technical and societal challenges. Current metrics suggest they are transitioning from novel aids to essential utilities—63% of enterprises now mandate their use. However, their ascendancy as the de facto standard hinges on addressing security flaws, mitigating cognitive erosion, and fostering equitable upskilling. For organizations, the optimal path lies in balanced integration: harnessing AI’s speed while preserving human ingenuity. As generative models evolve, developers who master this symbiosis will define the next epoch of software engineering.
Knowledge thats worth delivered in your inbox
Next Post
Loading More Posts
Connect with Us!
Thanks for reaching out
Our Sales Team will be in touch with you shortly.
Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.