


3 minutes, 38 seconds read
Published on Jan 31, 2020
Updated on Apr 24, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.
Automated compliance and control for global regulations.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(41)
Insurtech(67)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(25)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(154)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(24)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
The healthcare industry is getting a comprehensive digital facelift. Digital Health Systems (DHS) that use new digital technologies like artificial intelligence & robotics are delivering smarter healthcare services and better health outcomes to the masses. Health organizations are increasingly relying on them to improve care coordination, chronic disease management and the overall patient experience. These health systems are also alleviating repetitive administrative tasks from the roles of healthcare professionals, allowing them more time to practice actual healthcare.
The Modern Medical Enterprise draws on digital-enabled technologies such as telemedicine, AR/VR and remote-monitoring wearables to diagnose diseases and promote self-care. These applications rely on high-volume processing of patient data on a frequent basis. Healthcare organizations also need to share/receive this information securely over a distributed network. However, sharing patient information remains a challenge, while the inability to access these records in a time-sensitive manner can affect the time-to-treatment for patients.
Deploying digital health systems that are both compliant to regulatory standards and functionally stable for a large number of concurrent users requires significant manned effort. Moreover, QA teams comprised of manual testers may end up working on repetitive manual test case scenarios that can lead to challenges in scaling or rolling out new features.
How can the modern healthcare enterprise keep pace with issues posed by the safe deployment of their digital health systems? Automated Testing is a hallmark process of any digital transformation project. It gives enterprises the ability to shorten their release cycles and meet their business needs without affecting productivity or operations across the healthcare value chain. Test Automation also allows medical enterprises to run repeatable and extensible test cases against real-world scenarios.
The growth of DevOps and the rise of mobile-first applications are responsible for driving the growth of the test automation market globally. Today, enterprises are able to go faster-to-market owing to the technological advancements in quality assurance & testing.
For instance, in the case of a large US-based teleradiology firm that offers enterprise Imaging Solutions for improving patient care — a stable and reliable system mandated custom-built test automation frameworks. The medical technology company provides fast & secure access to diagnostic quality images using any web enabled device. To achieve this, they have built a cloud-based image sharing platform that allows digital image streaming, diagnostic & clinical viewing, and archiving for healthcare organizations.
Medical Image sharing among healthcare organizations is altogether brimming with security risks, and requires a complex network of systems to facilitate its smooth functioning.
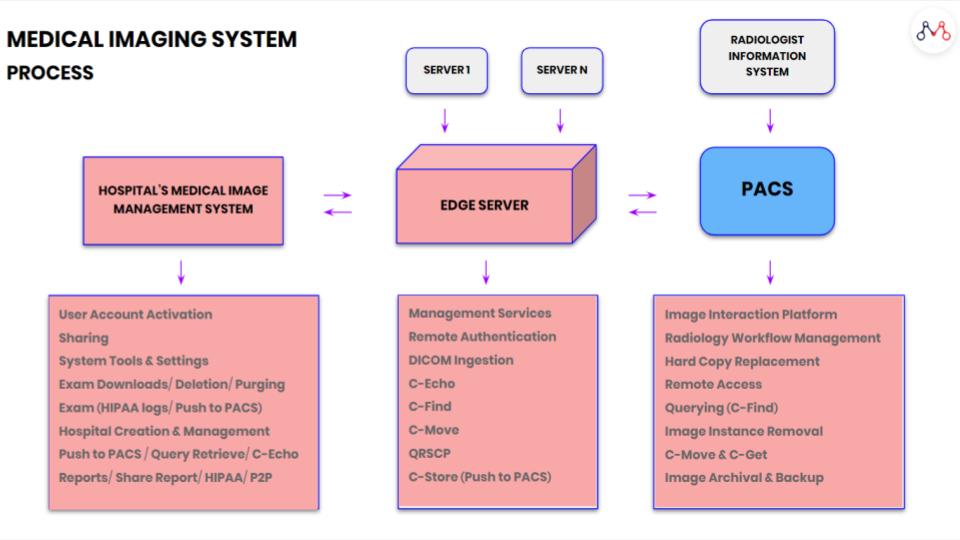
Also read – How are Medical Images shared among Healthcare Enterprises?
In order to fulfil their business objectives, Mantra Labs identified key challenges for their testing requirements, namely —
1. Scalability
The platform must be able to support a high number of concurrent users.
2. Fail-over Control
The platform should behave functionally correct under very high loads with stable fail-over capability.
3. Efficiency & Reliability
The platform must scale rapidly when supporting a large user base & multiple formats with minimal page navigation response time.
Several testing components were deployed along with test automation techniques to address the full range of QA issues, including: functional testing, integration testing, GUI testing, and regression testing.
Mantra Labs created a federated architecture to ensure near-perfect scaling, and true load & data isolation between different tenant organizations. The federated architecture consists of a number of deployments and a central set of components that stores global information like lists of organizations & users, and provides a centralized messaging service.
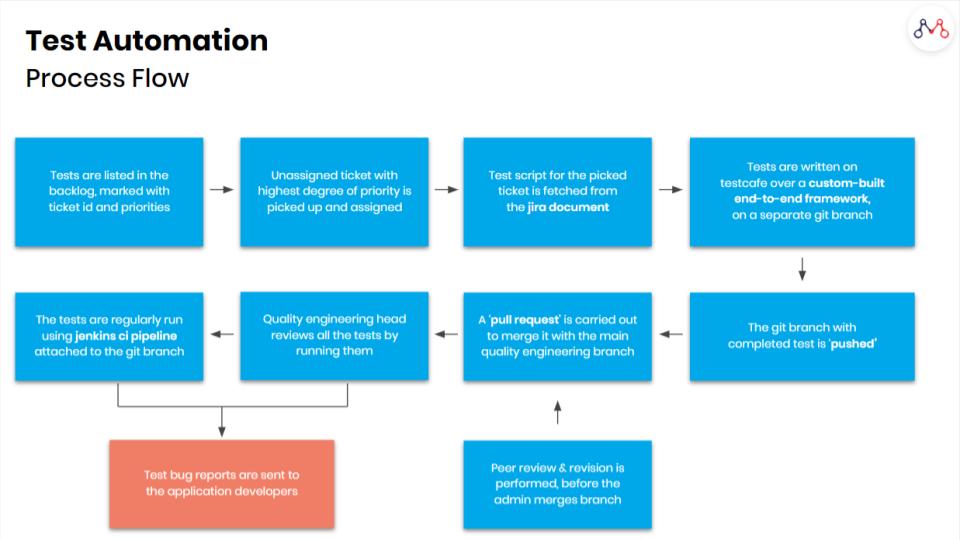
The entire cycle of bug detection in the UI, API and Server Loads involves several weeks of regression manual efforts. By automating tests, techniques like Stochastic Tests can be applied to detect bugs and reduce the overall cycle time.
Through Mantra Labs deep medical domain expertise, in-depth testing practices, intuitive suggestions for platform scaling and successful test automation efforts — significant business objectives were realised over the course for the client. Mantra was able to achieve over 60% reduction in cycle time, and about 65 per cent improvement in bug detection capability before the release cycle.
Nearly 35% of Executive Management objectives revolve around implementing quality checks early in the product life cycle, which can be achieved through test automation. For further queries and details about automated testing, please feel free to reach us at hello@mantralabsglobal.com
Related:
Knowledge thats worth delivered in your inbox
Smart Manufacturing starts with real-time visibility.
Manufacturing companies today generate data by the second through sensors, machines, ERP systems, and MES platforms. But without real-time insights, even the most advanced production lines are essentially flying blind.
Manufacturers are implementing real-time dashboards that serve as control towers for their daily operations, enabling them to shift from reactive to proactive decision-making. These tools are essential to the evolution of Smart Manufacturing, where connected systems, automation, and intelligent analytics come together to drive measurable impact.
Data is available, but what’s missing is timely action.
For many plant leaders and COOs, one challenge persists: operational data is dispersed throughout systems, delayed, or hidden in spreadsheets. And this delay turns into a liability.
Real-time dashboards help uncover critical answers:
By converting raw inputs into real-time manufacturing analytics, dashboards make operational intelligence accessible to operators, supervisors, and leadership alike, enabling teams to anticipate problems rather than react to them.
Line performance and downtime trends
Track OEE in real time and identify underperforming lines.
Predictive maintenance alerts
Utilize historical and sensor data to identify potential part failures in advance.
Inventory heat maps & reorder thresholds
Anticipate stockouts or overstocks based on dynamic reorder points.
Quality metrics linked to operator actions
Isolate shifts or procedures correlated with spikes in defects or rework.
These insights allow production teams to drive day-to-day operations in line with Smart Manufacturing principles.
Role-based dashboards
Dashboards can be configured for machine operators, shift supervisors, and plant managers, each with a tailored view of KPIs.
Embedded alerts and nudges
Real-time prompts, like “Line 4 below efficiency threshold for 15+ minutes,” reduce response times and minimize disruptions.
Cross-functional drill-downs
Teams can identify root causes more quickly because users can move from plant-wide overviews to detailed machine-level data in seconds.
Data lakehouse integration
Unified access to ERP, MES, IoT sensor, and QA systems—ensuring reliable and timely manufacturing analytics.
ETL pipelines
Real-time data ingestion from high-frequency sources with minimal latency.
Visualization tools
Custom builds using Power BI, or customized solutions designed for frontline usability and operational impact.
Mantra Labs partnered with a North American die-casting manufacturer to unify its operational data into a real-time dashboard. Fragmented data, manual reporting, delayed pricing decisions, and inconsistent data quality hindered operational efficiency and strategic decision-making.
As this case shows, real-time dashboards are not just operational tools—they’re strategic enablers.
(Learn More: Powering the Future of Metal Manufacturing with Data Engineering)
| Aspect | What You Should Know |
| 1. Why Static Reports Fall Short | Delayed insights after issues occur Disconnected systems (ERP, MES, sensors) No real-time alerts or embedded decision logic |
| 2. What Real-Time Dashboards Enable | Track OEE and downtime in real-time Predictive maintenance using sensor data Dynamic inventory heat maps Quality linked to operators |
| 3. Dashboards That Drive Action | Role-based views (operator to CEO) Embedded alerts like “Line 4 down for 15+ mins” Drilldowns from plant-level to machine-level |
| 4. What Powers These Dashboards | Unified Data Lakehouse (ERP + IoT + MES) Real-time ETL pipelines Power BI or custom dashboards built for frontline usability |
Smart Manufacturing dashboards aren’t just analytics tools—they’re productivity engines. Dashboards that deliver real-time insight empower frontline teams to make faster, better decisions—whether it’s adjusting production schedules, triggering preventive maintenance, or responding to inventory fluctuations.
Explore how Mantra Labs can help you unlock operations intelligence that’s actually usable.
Knowledge thats worth delivered in your inbox


Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
