


3 minutes, 13 seconds read
Published on Oct 23, 2020
Updated on Oct 28, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(3)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(39)
Insurtech(67)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(153)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(23)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
What do you call a prediction model that performs tremendously well on the same data it was trained on? Technically, a tosh! It will perform feebly on unseen data, thus leading to a state called overfitting.
To combat such a scenario, the dataset is split into train set and test set. The model is then trained on the train set and is kept deprived of the test set. This test set is utilized to estimate the efficacy of the model. To decide on the best train-test split, two competing cornerstones need to be focused on. Firstly, less training data will give rise to greater variance in the parameter estimates, and secondly, less testing data will lead to greater variance in the performance statistic. Conventionally, an 80/20 split is considered to be a suitable starting point such that neither variance is too high.
Yet another problem arises when we try to fine-tune the hyperparameters. There is a possibility for the model to still overfit on the testing data due to data leakage. To prevent this, a dataset should typically be divided into train, validation, and test sets. The validation set acts as an intermediary between the training part and the final evaluation part. However, this indeed reduces the training examples, thus making it less likely for the model to generalize, and the performance rather depends merely on a random split.
Here’s where cross-validation comes to our rescue!
Cross-validation (CV) eliminates the explicit requirement of a validation set. It facilitates the model selection and aids in gauging the generalizing capability of a model. The rudimentary modus operandi is the k-fold CV, where the dataset is split into k groups/folds and k-1 folds are used to train the model, while the held out kth fold is used to validate the model. Henceforth, each fold gets an opportunity to be used as a test set. This way, in each fold, the evaluation score is retained and the model is then discarded. The model’s skill is summarised by the mean of the evaluation scores. The variance of the evaluated scores is often expressed in terms of standard deviation.
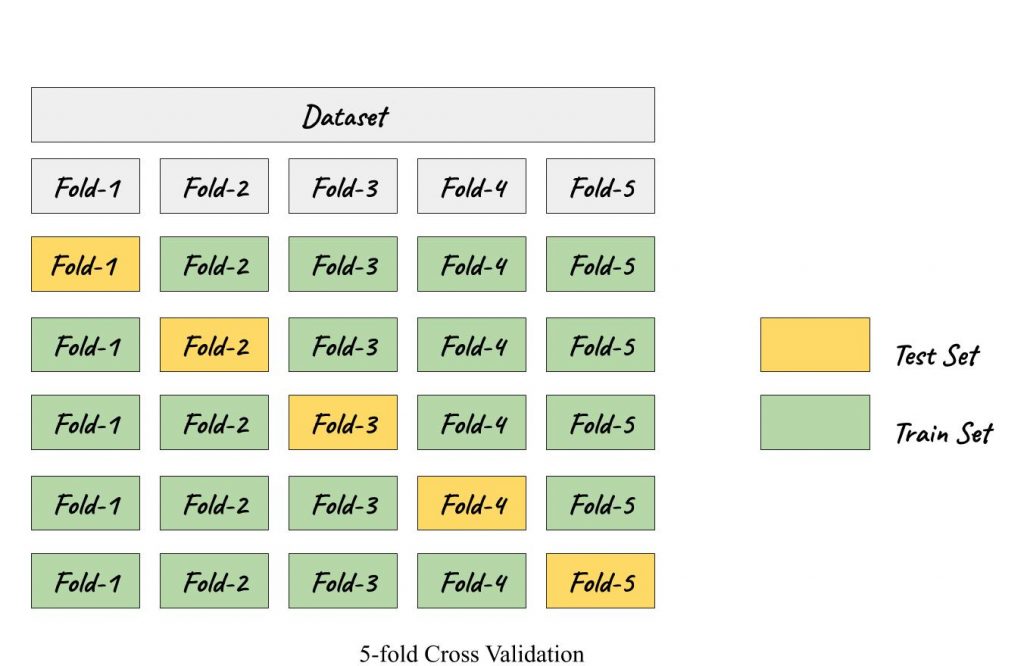
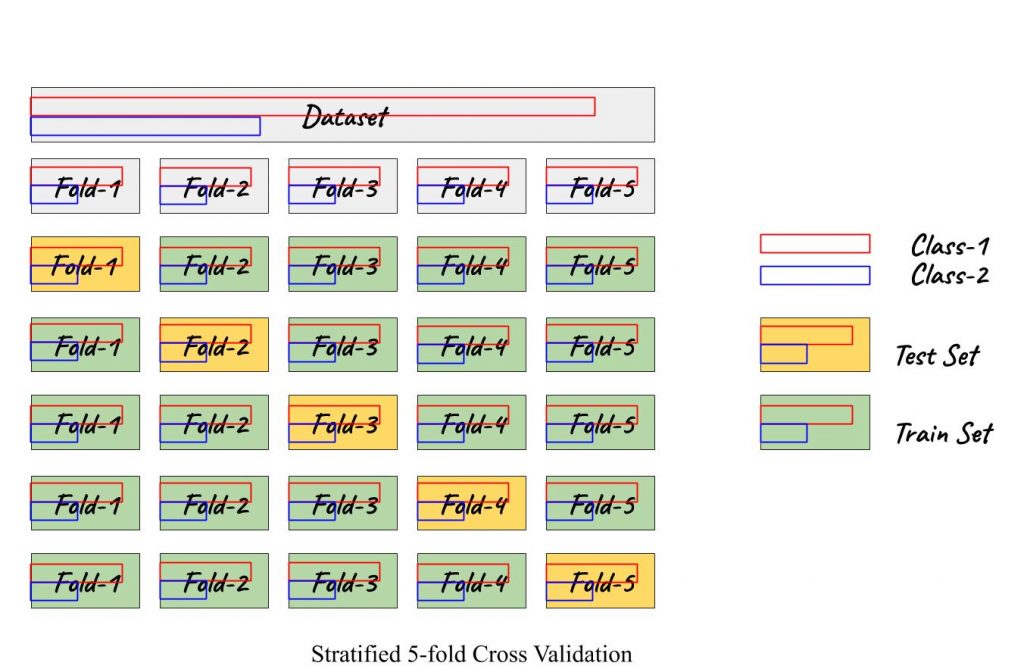
But is it feasible when the dataset is imbalanced?
Probably not! In case of imbalanced data an extension to k-fold CV, called Stratified k-fold CV proves to be the magic bullet. It maintains the class proportion in all the folds as it was in the original dataset, thus making it available for the model to train on both, the minority as well as majority classes.
Determining the value of k
This is a baffling concern though! Taking into account the bias-variance trade-off, the value of k should be decided carefully. Consequently, the k value should be chosen such that each fold can act as a representative of the dataset. Jumping on the bandwagon, it is preferred to set the k value as 5 or 10 since experimental success is observed with these values.
There are some other variations of cross-validation viz.,
Finally yet importantly, some tidbits that shouldn’t be ignored:
Voila! We finally made it! If the model evaluation scores are acceptably high and have low variance, it’s time to party hard! Our mojo has worked!
Knowledge thats worth delivered in your inbox
The insurance industry thrives on relationships—but it can only scale through efficiency, precision, and timely distribution. While much of the digital transformation buzz has focused on customer-facing portals, the real transformation is happening in the field, where modern sales apps are quietly driving a smarter, faster, and more empowered agent network.
Let’s explore how mobile-first sales enablement platforms are reshaping insurance sales across prospecting, onboarding, servicing, renewals, and growth.
Today’s insurance agent is not just a policy seller—they’re also a financial advisor, data gatherer, service representative, and the face of the brand. Yet many still rely on paper forms, disconnected tools, and manual processes.
That’s where intelligent sales apps come in—not just to digitize, but to optimize, personalize, and future-proof the entire agent journey.
Across the insurance value chain, sales agent apps have evolved into full-service platforms—streamlining operations, boosting conversions, and empowering agents in the field. These tools aren’t optional anymore, they’re critical to how modern insurers perform. Here’s how leading insurers are empowering their agents through technology:
Sales apps now empower agents to:
Agents spend significantly less time navigating through disjointed systems or chasing down information. With quick access to prioritized leads, appointment scheduling, and location tools—all in one app—they can focus more on meaningful customer interactions and closing sales, rather than administrative overhead.
Sales apps centralize post-sale activities such as:
Customers receive a consistent and seamless experience across touchpoints—whether online, in-person, or via mobile. With digital forms, real-time policy updates, and instant access to servicing tools, agents can handle post-sale tasks like renewals and claims faster, without paperwork delays—leading to improved satisfaction and higher retention.
Using smart tools, agents can:
Agents can conduct secure, interactive consultations from anywhere—sharing proposals, visual aids, and completing eKYC remotely. This not only expands their reach to customers in digital-first or geographically dispersed markets, but also builds greater trust through real-time engagement, clear communication, and a personalized advisory experience—all without needing a physical presence.
Modern insurance apps provide:
Field agents gain access to real-time performance insights, training modules, and incentive tracking—directly within the app. This empowers them to upskill on the go, stay motivated through transparent goal-setting, and make informed decisions that align with overall business KPIs. The result is a more agile, knowledgeable, and performance-driven sales force.
Advanced insurance apps support:
Even in low-connectivity or remote Tier 2 and 3 markets, agents can operate at full capacity—thanks to offline capabilities, secure authentication, and end-to-end sales execution tools. This ensures uninterrupted productivity, faster policy issuance, and adherence to compliance standards, regardless of location or network availability.
Some forward-thinking insurers are combining AI with health platforms to:
By integrating real-time health data from fitness trackers and wellness apps, insurers can offer hyper-personalized, preventive insurance products tailored to individual lifestyles. This empowers agents to move beyond transactional selling—becoming trusted advisors who recommend coverage based on customers’ health habits, life stages, and future needs, ultimately deepening engagement and improving long-term retention.
We help insurers go beyond surface-level digitization to build intelligent, mobile-first ecosystems that optimize agent efficiency and customer engagement—backed by real-world impact.
We partnered with a leading travel insurance provider to develop a high-performance agent workflow platform featuring:
This mobile-first solution empowered agents to close policies faster with significantly reduced paperwork and data entry time—improving agent productivity by 2x and enabling sales at scale.
For one of India’s leading health insurers, we helped implement a full-funnel engagement and analytics stack:
Whether you’re digitizing field sales, gamifying customer wellness, or fine-tuning your marketing engine, Mantra Labs brings the technology depth, insurance expertise, and user-first design to turn strategy into scalable execution.
If you’re ready to modernize your agent network – Get in touch with us to explore how we can build intelligent, mobile-first tools tailored to your distribution strategy. Just remember, the best sales apps aren’t just tools, they’re growth engines; and field sales success isn’t about more apps. It’s about the right workflows, in the right hands, at the right time.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
