


5 minutes, 29 seconds read
Published on May 30, 2019
Updated on Apr 24, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.
Automated compliance and control for global regulations.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(41)
Insurtech(67)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(25)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(154)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(24)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
For modern healthcare organizations, extending better patient care across the service continuum involves new challenges that surround sharing information over a distributed network. Effectively sharing patient information remains a challenge. However, the inability to access these records in a time-sensitive manner results in re-imaging and re-testing the patients. It affects both — ‘time-to-treatment’ and the bottom line. Effective medical image management thus becomes crucial for every digital healthcare enterprise.
The release process for medical images is altogether complicated — brimming with security related-risks. Images (such as X-Ray Scans, MRI scans, PET scans, etc.) are created and released across several departments and systems while being purposefully kept ‘out-of-reach’ from a host of unauthorized users.
Training & controls on release policies and procedures require ‘health information management’ expertise. It’s because image Handling (electronically) can become susceptible to data corruption, complex accessibility/sharing issues and high-security risks. All of these raise potential red flags for health information management (HIM) professionals.
So how does Medical Image sharing work in this environment? What, if any — are the safeguards surrounding the ‘release’ process?
Before we go further, let’s delve into the term ‘Medical Imaging’. According to the WHO, the technique embodies different imaging modalities and processes to image the human body (creating visual representations) for diagnostic and treatment purposes. — making it crucial for improving public health initiatives across all population groups.
First, the image is captured using a medical imaging device (routine imaging techniques like ultrasound, MRI, etc.). Then it is necessary to archive and store the images for future use and further processing. Unlike regular images (.png, .jpeg), medical images use DICOM format for storage. DICOM is Digital Imaging and Communication in Medicine standard. The medical practitioner responsible for acquiring and interpreting such medical images is a ‘Radiologist’. And the system they rely on for storing electronic image data is ‘PACS’ (Picture Archiving and Communication System).
If a healthcare organization or an outside consultant (physician, clinician) needs access to an individual patient’s medical images, then the access and retrieval will have to go through PACS. Typically, a Radiologist has authority to control and operate PACS.
Here is a simple process diagram of a medical imaging system —
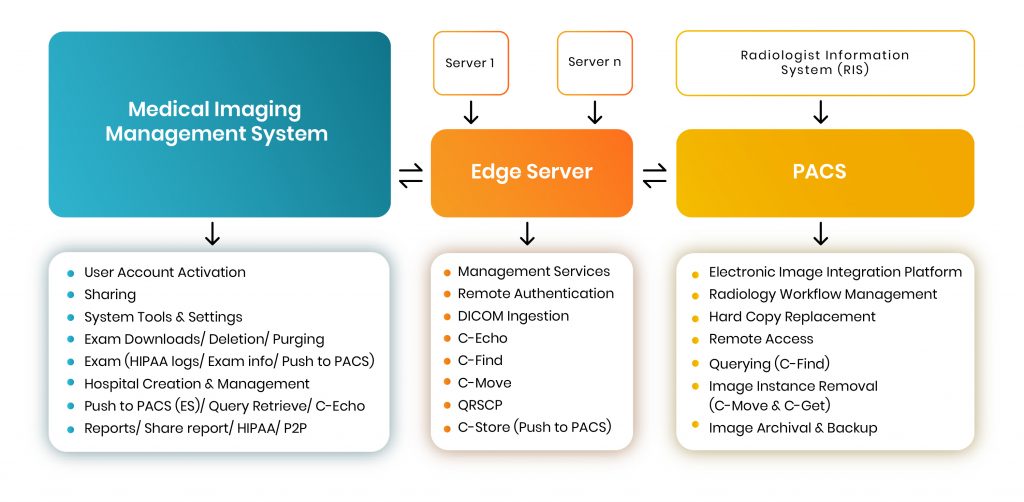
A Typical HIPAA-compliant Medical Imaging Management System places a request (for a specific file) to ‘PACS’ via an intermediary system known as ‘Edge Server’. The sole purpose of the Edge Server is to function as a request-node so that other hospitals or physicians can contact the particular radiologist (who possesses the images stored in PACS) and place a request to access a copy of the file in question.
[Related: Modern Medical Enterprises Absolutely Need Test Automation. Here’s Why.]
Critical use cases arise for medical image sharing involving support for:
Typically, PACS store digital medical images locally for retrieval. A PACS consists of four major components:
To communicate with the PACS server we use DICOM messages that are similar to DICOM image ‘headers”, but with different attributes. The Edge Server manages several functions that allow users to sort through hundreds of thousands of large-volume data and retrieve a specific file from a database either stored in ‘PACS’ or on the ‘MIMS’.
Each of the three highlighted sections (see diagram) can perform various functions, while communication is defined through specific rules and standards that are legally enforced and universally followed.
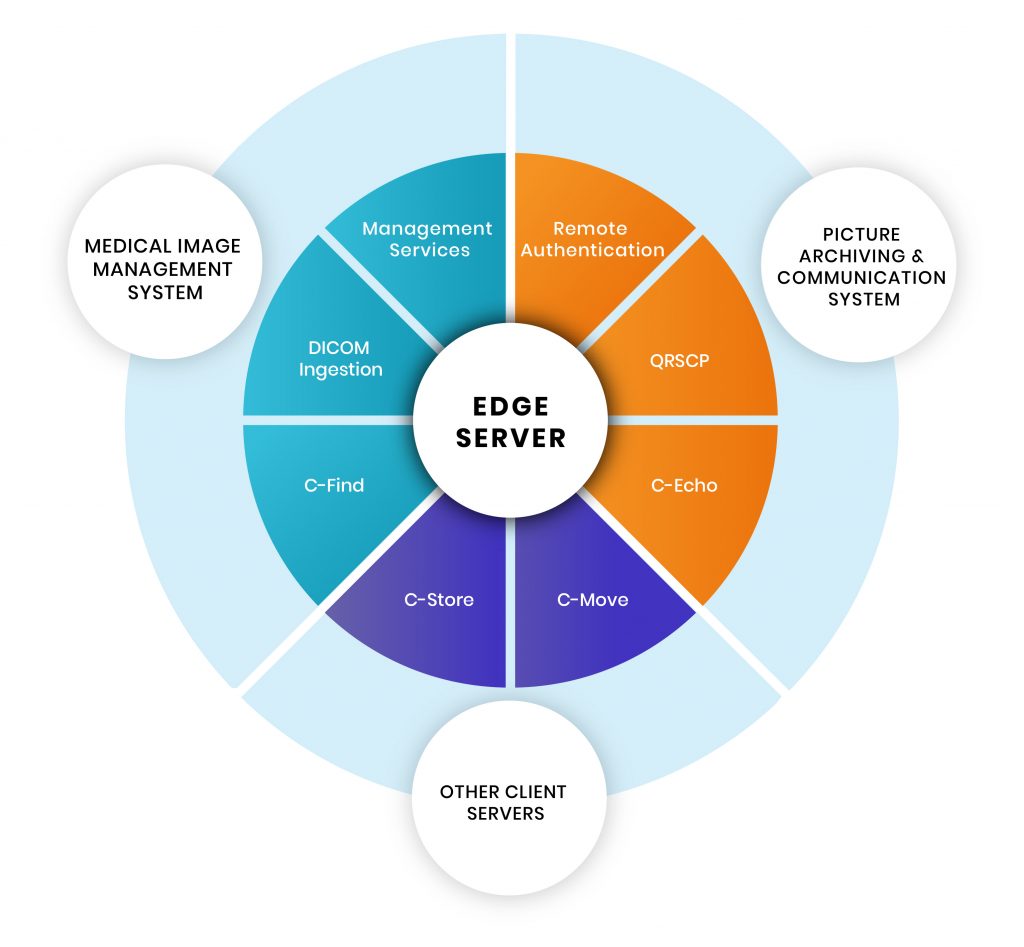
Through the ‘Edge Server’, we can access images stored in PACS. The ‘Management Services’ operation is the first and foremost feature. It means that a user can control & maintain the complete functionality of the server through this. Using ‘Remote Authentication’, users can obtain centralized authorization and authentication to request files from PACS. Please note, Remote Authentication is a networking protocol operating by way of specific ports.
To verify basic DICOM connectivity to the server — i.e, to check if the server is live or not, a C-Echo message is sent to ping the server, after which it will wait for its response. Once identifying the server as live, a user can perform querying and retrieval-based operations. Next, the user can begin the process of requesting DICOM images from the Medical Image Management System — known as ‘Ingestion’. DICOM Ingestion involves pre-assigned IP and port addresses (default ports are 2104-2111).
Client: First, it’s important to check the location of the specific image(s) on a particular server. For this, a query-based C-FIND operation sends a request to the server. The user establishes a network connection to the PACS server and prepares a C-FIND request message (which is a list of DICOM attributes). The user then fills in the C-FIND request message with ‘keys’ that match. (E.g. to query for a patient ID, the user fills the patient ID attribute with the patient’s ID.) Then, the C-FIND request message is sent to the server.
Server: The server reverts a list of C-FIND response messages. Each of these messages contain a list of DICOM attributes with values for each match. It then initiates C-MOVE request using the DICOM network protocol to retrieve images from the PACS server.
One can retrieve images at the Study, Series or Image (instance) level. The C-MOVE request specifies where the retrieved instances should be sent (using separate C-STORE messages). The C-STORE operation, also known as DICOM Push simply pushes (sends) the images to the PACS server (or P2P — Push to PACS).
C-STORE message implements the DICOM storage service. The SCU sends a C-STORE-RQ (request) message to the server, which includes the actual dataset to transfer. The server answers by returning a C-STORE-RSP (response) message to the user, communicating success or failure of the storage request.
Using DICOM images, health management professionals, physicians, and radiologists can utilize secure protocols in handling confidential medical image data. It extends the ability to view such images discreetly and instantly; avoiding duplication costs; and reducing unnecessary radiation exposure to patients.
Medical Image Sharing furthers the “Health 2.0” initiative by being able to instantly and electronically exchange medical information between physicians, as well as with patients — improving communication within the industry.
[Related: How AI is innovating healthcare sector?]
About the author: Rijin Raj is a Senior Software Engineer-QA at Mantra Labs, Bangalore. He is a seasoned tester and backbone of the organization with non-compromising attention to details.
Related:
DICOM stands for — Digital Imaging and Communication. It is a medical standard for sharing a patient’s MRI, X-ray, and other image files over the internet.
Unlike regular images (png, jpg, etc.) DICOM is a secure format for storing confidential medical images. Usually, PACS (Picture Archiving and Communication System) and MIMS (Medical Image Management System) are used to store DICOM Images.
DICOM is used for securely storing and retrieving confidential images in distributed networks (internet).
Using DICOM images, health management professionals, physicians, and radiologists can securely handle confidential medical image data.
Knowledge thats worth delivered in your inbox
Smart Manufacturing starts with real-time visibility.
Manufacturing companies today generate data by the second through sensors, machines, ERP systems, and MES platforms. But without real-time insights, even the most advanced production lines are essentially flying blind.
Manufacturers are implementing real-time dashboards that serve as control towers for their daily operations, enabling them to shift from reactive to proactive decision-making. These tools are essential to the evolution of Smart Manufacturing, where connected systems, automation, and intelligent analytics come together to drive measurable impact.
Data is available, but what’s missing is timely action.
For many plant leaders and COOs, one challenge persists: operational data is dispersed throughout systems, delayed, or hidden in spreadsheets. And this delay turns into a liability.
Real-time dashboards help uncover critical answers:
By converting raw inputs into real-time manufacturing analytics, dashboards make operational intelligence accessible to operators, supervisors, and leadership alike, enabling teams to anticipate problems rather than react to them.
Line performance and downtime trends
Track OEE in real time and identify underperforming lines.
Predictive maintenance alerts
Utilize historical and sensor data to identify potential part failures in advance.
Inventory heat maps & reorder thresholds
Anticipate stockouts or overstocks based on dynamic reorder points.
Quality metrics linked to operator actions
Isolate shifts or procedures correlated with spikes in defects or rework.
These insights allow production teams to drive day-to-day operations in line with Smart Manufacturing principles.
Role-based dashboards
Dashboards can be configured for machine operators, shift supervisors, and plant managers, each with a tailored view of KPIs.
Embedded alerts and nudges
Real-time prompts, like “Line 4 below efficiency threshold for 15+ minutes,” reduce response times and minimize disruptions.
Cross-functional drill-downs
Teams can identify root causes more quickly because users can move from plant-wide overviews to detailed machine-level data in seconds.
Data lakehouse integration
Unified access to ERP, MES, IoT sensor, and QA systems—ensuring reliable and timely manufacturing analytics.
ETL pipelines
Real-time data ingestion from high-frequency sources with minimal latency.
Visualization tools
Custom builds using Power BI, or customized solutions designed for frontline usability and operational impact.
Mantra Labs partnered with a North American die-casting manufacturer to unify its operational data into a real-time dashboard. Fragmented data, manual reporting, delayed pricing decisions, and inconsistent data quality hindered operational efficiency and strategic decision-making.
As this case shows, real-time dashboards are not just operational tools—they’re strategic enablers.
(Learn More: Powering the Future of Metal Manufacturing with Data Engineering)
| Aspect | What You Should Know |
| 1. Why Static Reports Fall Short | Delayed insights after issues occur Disconnected systems (ERP, MES, sensors) No real-time alerts or embedded decision logic |
| 2. What Real-Time Dashboards Enable | Track OEE and downtime in real-time Predictive maintenance using sensor data Dynamic inventory heat maps Quality linked to operators |
| 3. Dashboards That Drive Action | Role-based views (operator to CEO) Embedded alerts like “Line 4 down for 15+ mins” Drilldowns from plant-level to machine-level |
| 4. What Powers These Dashboards | Unified Data Lakehouse (ERP + IoT + MES) Real-time ETL pipelines Power BI or custom dashboards built for frontline usability |
Smart Manufacturing dashboards aren’t just analytics tools—they’re productivity engines. Dashboards that deliver real-time insight empower frontline teams to make faster, better decisions—whether it’s adjusting production schedules, triggering preventive maintenance, or responding to inventory fluctuations.
Explore how Mantra Labs can help you unlock operations intelligence that’s actually usable.
Knowledge thats worth delivered in your inbox


Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
