


Published on Aug 2, 2019
Updated on Oct 16, 2019
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(20)
Clean Tech(8)
Customer Journey(17)
Design(44)
Solar Industry(8)
User Experience(67)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(29)
Technology Modernization(8)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(38)
Insurtech(66)
Product Innovation(57)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(146)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(7)
Computer Vision(8)
Data Science(21)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(47)
Natural Language Processing(14)
For any operational effort across large organizations, a significant amount of time and resources are spent manually inputting data into downstream systems. These processes more specifically affect insurance practices that are deeply reliant on back-office processes. The bulk of the insurance workforce is condensed into operations and support functions (e.g. policy issuance and servicing). Here, data is typically unstructured and locked away in heaps of paper-based documents, emails, scanned images, excel worksheets, pdf, and word reports.
Typically in insurance, at least 90% of unstructured documents are manually processed, while an ‘Insurance Policy Administration System’ is on average between 15–20 years old — forcing them at times to lag behind their financial services peers.
To make the most out of the massive quanta of inbound data stored in siloed systems, firms have recently begun to take a serious look at streamlining data migration using AI-based tools. The burgeoning reality is that a tremendous amount of man-hours are wasted in repetitive tasks leading to increased processing times and slower through rates for insurance.
Proportion of Unstructured Data in P&C Insurance (%)
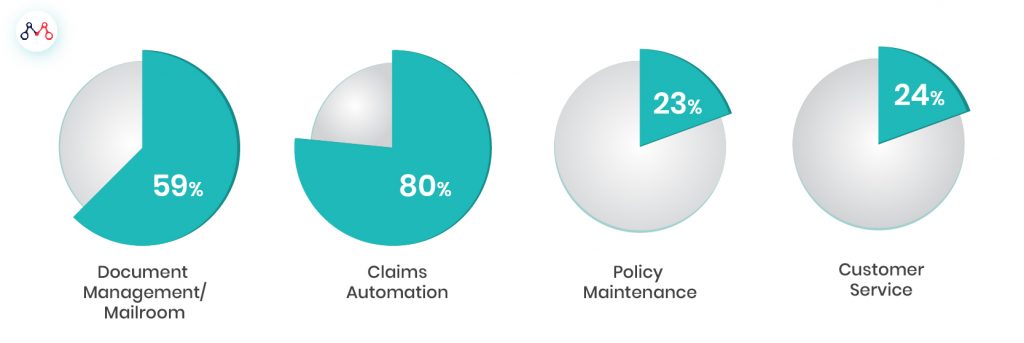
Source: SPS Data
AI Gets Holed Up In Silos
According to a recent IDG study titled the ‘Future of Work’, less than 50% of global enterprises have deployed intelligent automation technologies (such as AI, Cognitive Automation or RPA), while over two-thirds find greater difficulty in integrating these people, process and AI. Over fifty percent of enterprises identify siloed deployments and overwhelmed internal application development teams as long-term issues. This can create friction between teams operating in silos and those trying to derive insights from unstructured docs. Nearly a third of enterprises identified getting AI into production and live services as the single biggest challenge to overcome.
According to a McKinsey paper, intelligent process automation is at the core of next-generation operational business models.
The Need For Intelligent Document Processing
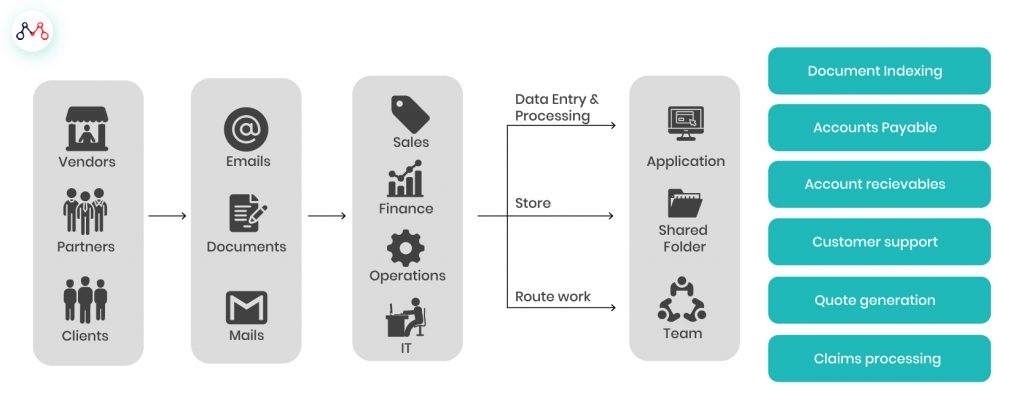
Source: Imaginea
A New Platform
MantraLabs has launched a unique solution to address the insurer’s pain-point through an intelligent platform built especially for silos, The solution addresses several dependency issues and is built to scale, making it a vendor-neutral platform that doesn’t require deep coding skills. The christened solution is FlowMagic — a simple and easy to use visual AI platform for insurer workflows.
FlowMagic applies proprietary AI techniques, Machine Learning and NLP, to extract any target data from unstructured documents. At the recently convened 4th Annual Insurance India Summit and Awards 2019 held in Mumbai, Mantra Labs presented a live demonstration of FlowMagic’s unique capabilities. Mantra Labs CEO Parag Sharma took the opportunity while speaking in front of industry leaders and attendees, to showcase our true AI-first approach to solving insurance challenges. FlowMagic truly embodies the spirit of that approach in tackling the problems plaguing traditional insurers — such as reducing document delivery times to the back-office by 80%.
FLOWMAGIC DASHBOARD

Customizable Workflows
The platform is equipped with plug and play capability. Using quick drag and drop, one can create custom workflows to address the most pressing operational functions, such as insurance agent onboarding or verifying medical invoices. Mantra Labs has pre-built over 50 AI-powered apps for its users to take advantage of. The open platform also allows insurers to create their own apps that can be seamlessly integrated.

FLOW MAGIC’s IN-BUILT APPS
By leveraging machine learning, insurers can use FlowMagic to shift intensive operational functions into auto-pilot. The AI tool can automate the ‘classify, extract, and validate’ cycle for insurers and direct decision-ready insights straight to decision-makers.
Although declining, the Insurance field is still paper-intensive. Insurers are shifting towards AI-powered engines to replace unnecessary manned effort behind redundant operational tasks. These systems can bring about at least a 70% reduction in manual processing and 30% improvement in cost-efficiencies throughout the value chain.
To know more about how FlowMagic is helping insurance leaders cognitively automate complex processes, reach out to us at hello@mantralabsglobal.com
Knowledge thats worth delivered in your inbox
In 1997, the world watched in awe as IBM’s Deep Blue, a machine designed to play chess, defeated world champion Garry Kasparov. This moment wasn’t just a milestone for technology; it was a profound demonstration of data’s potential. Deep Blue analyzed millions of structured moves to anticipate outcomes. But imagine if it had access to unstructured data—Kasparov’s interviews, emotions, and instinctive reactions. Would the game have unfolded differently?
This historic clash mirrors today’s challenge in data architectures: leveraging structured, unstructured, and hybrid data systems to stay ahead. Let’s explore the nuances between Data Warehouses, Data Lakes, and Data Lakehouses—and uncover how they empower organizations to make game-changing decisions.
Deep Blue’s triumph was rooted in its ability to process structured data—moves on the chessboard, sequences of play, and pre-defined rules. Similarly, in the business world, structured data forms the backbone of decision-making. Customer transaction histories, financial ledgers, and inventory records are the “chess moves” of enterprises, neatly organized into rows and columns, ready for analysis. But as businesses grew, so did their need for a system that could not only store this structured data but also transform it into actionable insights efficiently. This need birthed the data warehouse.
Data warehouses act as the strategic command centers for enterprises. By employing a schema-on-write approach, they ensure data is cleaned, validated, and formatted before storage. This guarantees high accuracy and consistency, making them indispensable for industries like finance and healthcare. For instance, global banks rely on data warehouses to calculate real-time risk assessments or detect fraud—a necessity when billions of transactions are processed daily, tools like Amazon Redshift, Snowflake Data Warehouse, and Azure Data Warehouse are vital. Similarly, hospitals use them to streamline patient care by integrating records, billing, and treatment plans into unified dashboards.
The impact is evident: according to a report by Global Market Insights, the global data warehouse market is projected to reach $30.4 billion by 2025, driven by the growing demand for business intelligence and real-time analytics. Yet, much like Deep Blue’s limitations in analyzing Kasparov’s emotional state, data warehouses face challenges when encountering data that doesn’t fit neatly into predefined schemas.
The question remains—what happens when businesses need to explore data outside these structured confines? The next evolution takes us to the flexible and expansive realm of data lakes, designed to embrace unstructured chaos.
While structured data lays the foundation for traditional analytics, the modern business environment is far more complex, organizations today recognize the untapped potential in unstructured and semi-structured data. Social media conversations, customer reviews, IoT sensor feeds, audio recordings, and video content—these are the modern equivalents of Kasparov’s instinctive reactions and emotional expressions. They hold valuable insights but exist in forms that defy the rigid schemas of data warehouses.
Data lake is the system designed to embrace this chaos. Unlike warehouses, which demand structure upfront, data lakes operate on a schema-on-read approach, storing raw data in its native format until it’s needed for analysis. This flexibility makes data lakes ideal for capturing unstructured and semi-structured information. For example, Netflix uses data lakes to ingest billions of daily streaming logs, combining semi-structured metadata with unstructured viewing behaviors to deliver hyper-personalized recommendations. Similarly, Tesla stores vast amounts of raw sensor data from its autonomous vehicles in data lakes to train machine learning models.
However, this openness comes with challenges. Without proper governance, data lakes risk devolving into “data swamps,” where valuable insights are buried under poorly cataloged, duplicated, or irrelevant information. Forrester analysts estimate that 60%-73% of enterprise data goes unused for analytics, highlighting the governance gap in traditional lake implementations.
This gap gave rise to the data lakehouse, a hybrid approach that marries the flexibility of data lakes with the structure and governance of warehouses. The lakehouse supports both structured and unstructured data, enabling real-time querying for business intelligence (BI) while also accommodating AI/ML workloads. Tools like Databricks Lakehouse and Snowflake Lakehouse integrate features like ACID transactions and unified metadata layers, ensuring data remains clean, compliant, and accessible.
Retailers, for instance, use lakehouses to analyze customer behavior in real time while simultaneously training AI models for predictive recommendations. Streaming services like Disney+ integrate structured subscriber data with unstructured viewing habits, enhancing personalization and engagement. In manufacturing, lakehouses process vast IoT sensor data alongside operational records, predicting maintenance needs and reducing downtime. According to a report by Databricks, organizations implementing lakehouse architectures have achieved up to 40% cost reductions and accelerated insights, proving their value as a future-ready data solution.
As businesses navigate this evolving data ecosystem, the choice between these architectures depends on their unique needs. Below is a comparison table highlighting the key attributes of data warehouses, data lakes, and data lakehouses:
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
| Data Type | Structured | Structured, Semi-Structured, Unstructured | Both |
| Schema Approach | Schema-on-Write | Schema-on-Read | Both |
| Query Performance | Optimized for BI | Slower; requires specialized tools | High performance for both BI and AI |
| Accessibility | Easy for analysts with SQL tools | Requires technical expertise | Accessible to both analysts and data scientists |
| Cost Efficiency | High | Low | Moderate |
| Scalability | Limited | High | High |
| Governance | Strong | Weak | Strong |
| Use Cases | BI, Compliance | AI/ML, Data Exploration | Real-Time Analytics, Unified Workloads |
| Best Fit For | Finance, Healthcare | Media, IoT, Research | Retail, E-commerce, Multi-Industry |
The interplay between data warehouses, data lakes, and data lakehouses is a tale of adaptation and convergence. Just as IBM’s Deep Blue showcased the power of structured data but left questions about unstructured insights, businesses today must decide how to harness the vast potential of their data. From tools like Azure Data Lake, Amazon Redshift, and Snowflake Data Warehouse to advanced platforms like Databricks Lakehouse, the possibilities are limitless.
Ultimately, the path forward depends on an organization’s specific goals—whether optimizing BI, exploring AI/ML, or achieving unified analytics. The synergy of data engineering, data analytics, and database activity monitoring ensures that insights are not just generated but are actionable. To accelerate AI transformation journeys for evolving organizations, leveraging cutting-edge platforms like Snowflake combined with deep expertise is crucial.
At Mantra Labs, we specialize in crafting tailored data science and engineering solutions that empower businesses to achieve their analytics goals. Our experience with platforms like Snowflake and our deep domain expertise makes us the ideal partner for driving data-driven innovation and unlocking the next wave of growth for your enterprise.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
