



Published on May 1, 2023
The slingshot effect of COVID-19 on distance learning contributed to the ed-tech boom in 2020–2022. Keeping an optimal user experience became crucial for ed-tech rivals to obtain a maximum user base and supply high-quality learning solutions to learners. This was due to the huge volume of tech goods on websites and apps aiming to impart education. Due to the remarkable changes in career opportunities and the need for upskilling for them, the trend of remote education is still popular and in great demand. This trend is especially evident in upskilling and test preparation. And there is increased demand to maintain a good user experience with ed-tech products. Here are some essential UX practices for Ed-tech:
- Accessibility:
It is crucial to make sure that all users, including those with disabilities, can access ed-tech platforms. This includes tools like text-to-speech choices, closed captioning, and screen readers. Additionally, a user-friendly interface should be included in the platform’s architecture. This makes it simple for users to explore and locate the data they require. One example below about accessibility:
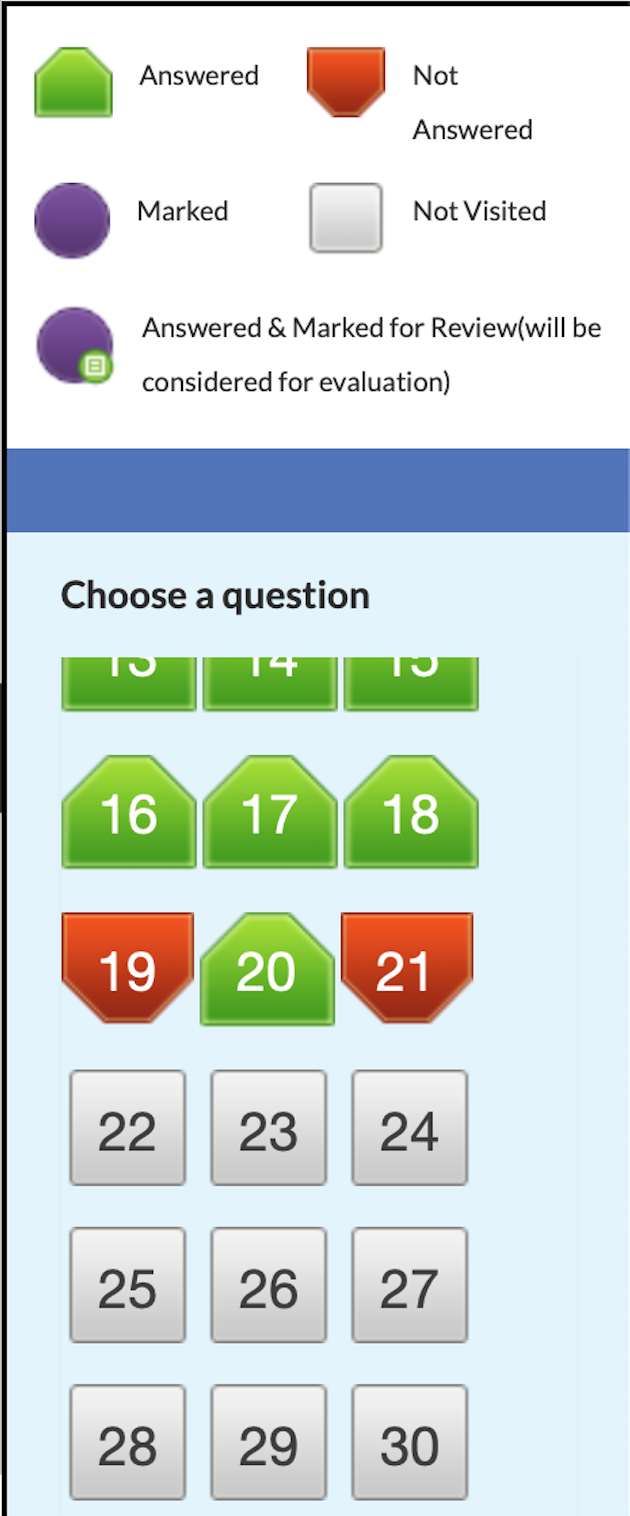
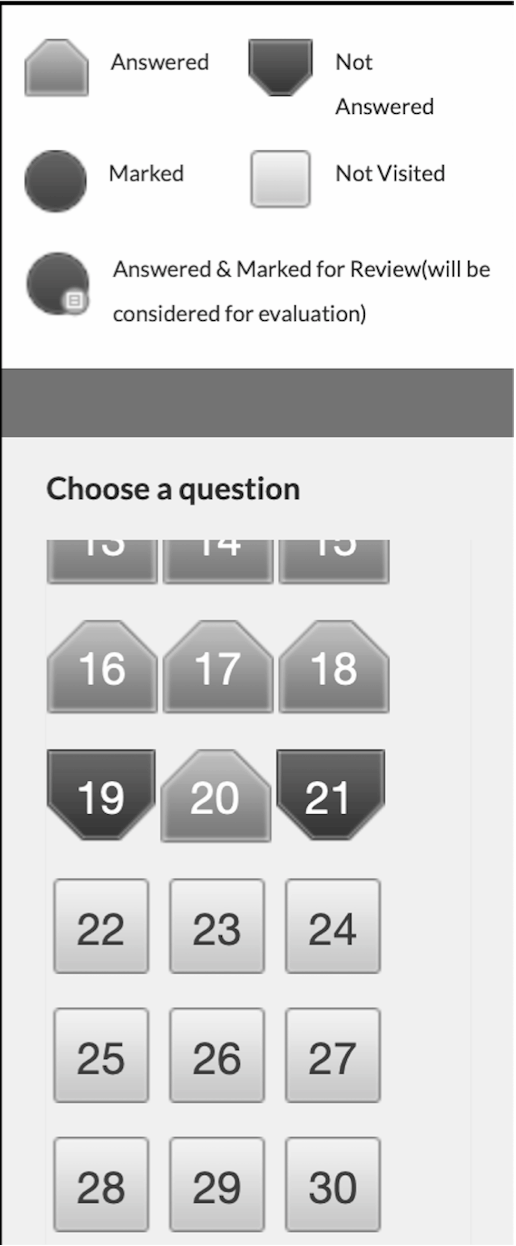
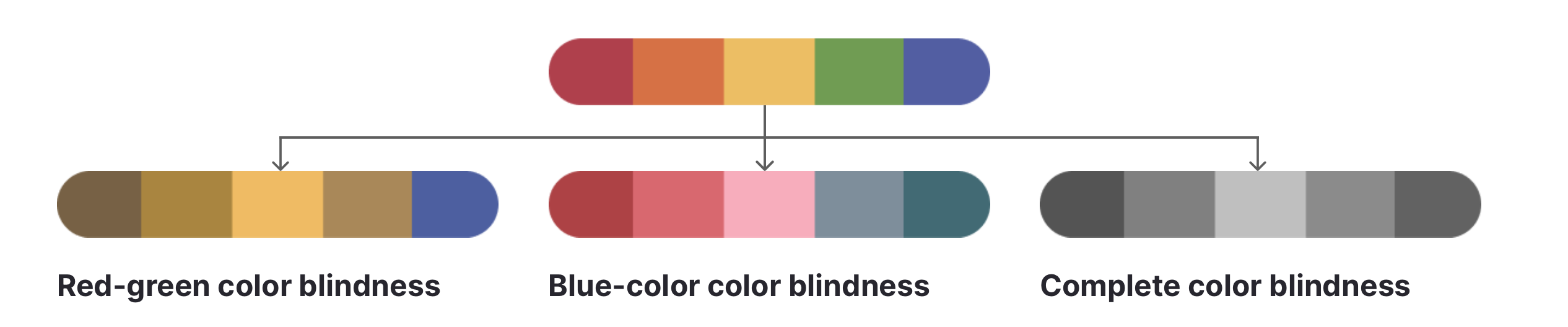
The above picture is an interface design for the nationally adopted format of the online examination. It has been designed to make the system accessible for people with color blindness (1 of every 12 people in the world is color blind). With the help of the legends, the students navigate questions with color and shape recognition. Observe the shape and color used for ‘answered’ and ‘not answered’ which are in green and red, respectively. If the shape had not been different, it would have been difficult for a student with color blindness to recognize which question is answered, which one is not, and which question is marked for review. Different shapes break the consistency in design elements as per some UI design rules, but this is necessary due to accessibility.


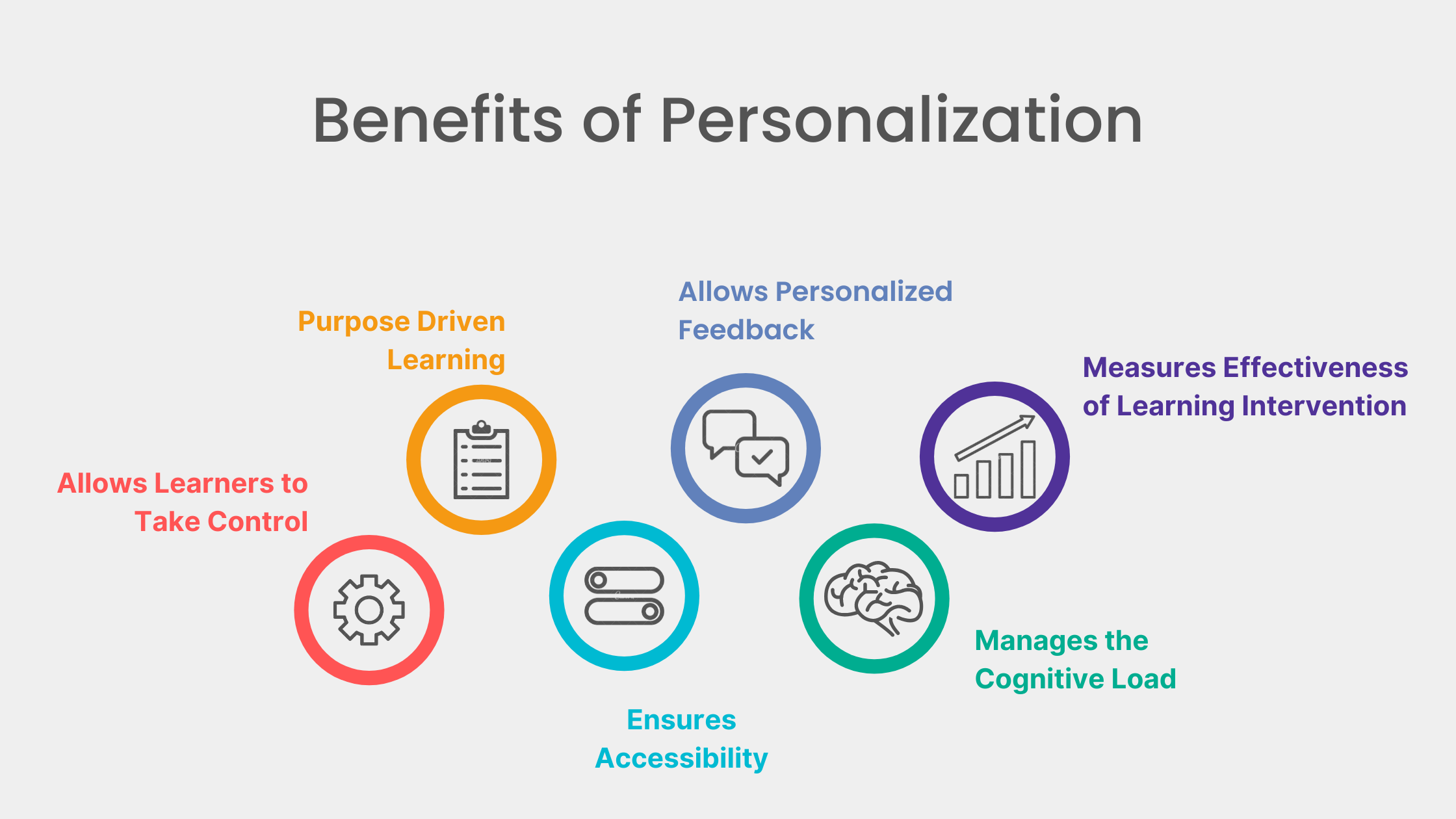
- Personalization:
Our learning at school was organic and nurturing due to the personal connection each student had with the teachers. When we talk about education, there should be a personal connection between the students and the system to boost students’ learning. Platforms for ed-tech should be created to meet the behavior and demands of every student. This entails tailoring feedback, designing a learning path specifically for each student, and personalizing the educational experience. This strategy boosts student enthusiasm and engagement, which will result in better learning outcomes.
- Gamification:
Gamification has been one of the most important and essential UX practices in ed-tech and education. By adding game-like components like incentives, points, and badges, gamification techniques can be utilized to improve the learning experience. Learning can become more enjoyable and interesting as a result, especially for younger children.
- Collaboration and feedback:
Edtech platforms should make it easier for students and teachers to collaborate, as it is a crucial component of the learning process. Features like collaborative projects, discussion boards, and video conferencing fall under this category.
Giving feedback on time is essential for the learning process. Platforms for education technology should provide feedback on students’ progress along with suggestions for what might be done better. Students who are driven and interested in their studies may benefit from this. While building an ed-tech platform, it’s crucial to build features for smooth collaboration among learners, educators, and administration.
- Mobile optimization:
Ed-tech platforms should be mobile-optimized given the rising use of mobile devices. This entails creating an interface that is appropriate for mobile use, providing mobile-specific functionality, and making sure the platform is usable on a range of devices.
Note: Soon an upcoming blog will have a detailed view of “mobile optimization” in ed-tech. Keep reading Mantra Labs’ blog post.
- Data analytics:
Data analytics systems for ed-tech platforms should be able to monitor student progress, pinpoint areas for development, and give teachers feedback. This can assist teachers in modifying their instruction to better meet the needs of each student.
- Continuous improvement:
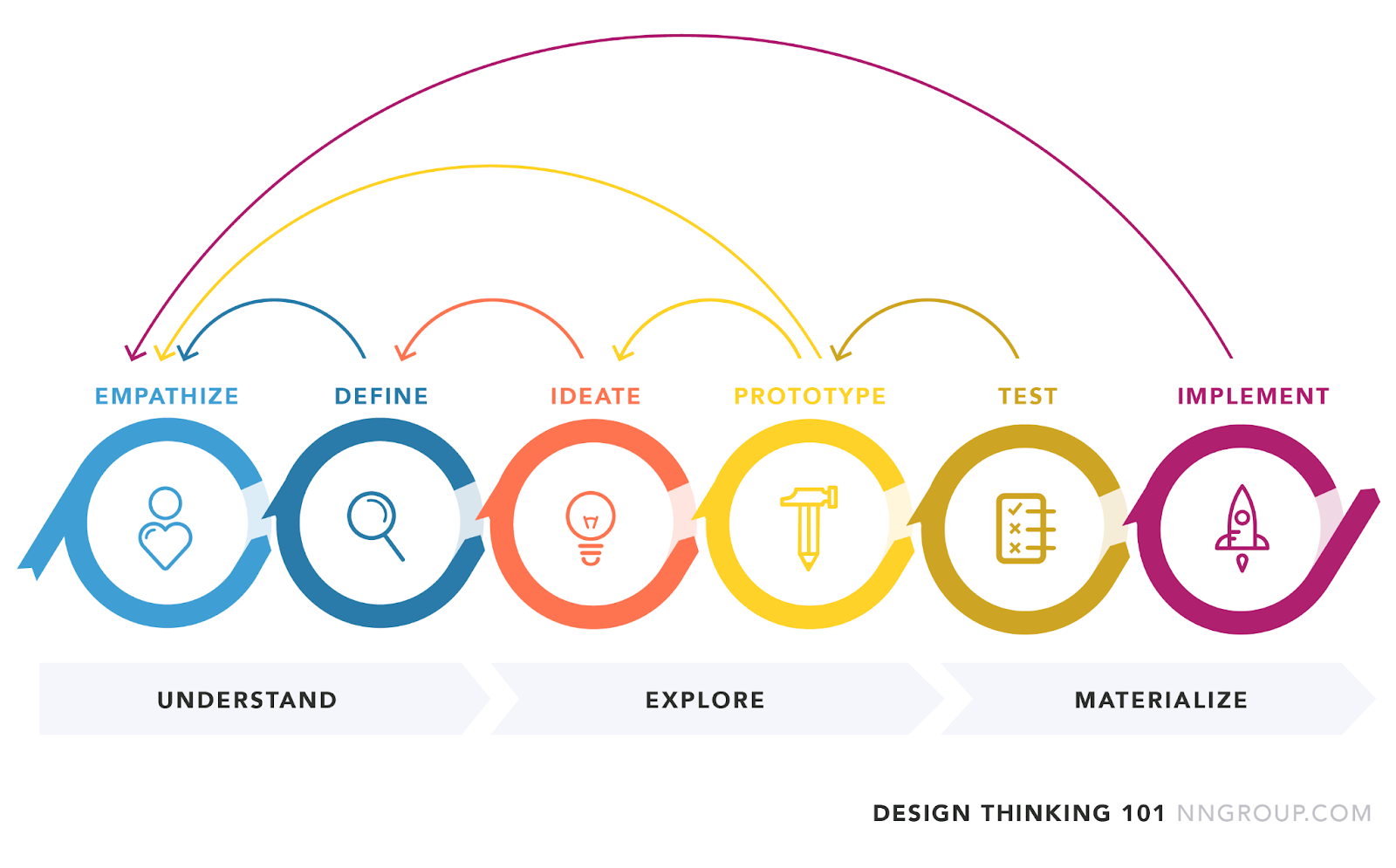
Last but not least, ed-tech platforms must be created with ongoing improvement in mind. This includes ongoing upgrades and enhancements based on user input and the most recent developments in ed-tech. Platforms should be built with scalability in mind so that they may change and evolve as requirements do. The Design Thinking process will help in creating such a system that will help students, teachers, and the company from all angles in this situation by making, remaking, and continuously refining the system.
Key takeaways:
- Prioritize accessibility and personalization to create a user-friendly learning experience for all students.
- Personalization in design creates strong and nurturing connections between the system and students.
- Incorporate gamification to increase student engagement and motivation.
- Provide collaboration and feedback features to improve engagement in the learning process.
- Optimize ed-tech platforms for mobile use to cater to the growing use of mobile devices.
- Utilize data analytics to track student progress and identify areas for improvement.
- Continuously improve ed-tech platforms based on user feedback and the latest industry trends.
About the Author:
Vijendra is currently working as a Sr. UX Designer at Mantra Labs. He is passionate about UX Research and Product Design.
Knowledge thats worth delivered in your inbox




