


Published on Jun 28, 2020
Updated on Jul 28, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(5)
Manufacturing(3)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(38)
Insurtech(66)
Product Innovation(58)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(153)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(23)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
En 2010, con el lanzamiento de Image Net Competition, un vasto conjunto de datos de aproximadamente 14 millones de imágenes etiquetadas fue hecho el código abierto para inspirar el desarrollo de clasificadores de la imagen de la vanguardia se convirtió en código abierto para inspirar el desarrollo de clasificadores de imágenes de vanguardia. Esto fue cuando la tecnología de aprendizaje profundo tuvo un gran avance y desde entonces no ha habido retroceso en los avances en este campo.
Diferentes industrias están utilizando activamente el Aprendizaje Profundo para la detección de objetos, etiquetado de características, análisis de imágenes, análisis de sentimientos y procesamiento de datos a velocidades extremadamente altas. El mayor beneficio que diferencia a Aprendizaje Profundo de otras tecnologías de IA (inteligencia artificial) y ML (el aprendizaje automático) es la capacidad de entrenar grandes cantidades de datos no estructurados casi en tiempo real. Las organizaciones con un fuerte enfoque en los datos ya tienen aproximadamente 1.5 veces más probabilidades de invertir en Aprendizaje Profundo para obtener información procesable: predice Forrester.
¿Qué hace que la tecnología de aprendizaje profundo sea tan buscada?
Echemos un vistazo a 5 casos de uso de aprendizaje profundo desde una perspectiva de los seguros.
Aprendizaje Profundo (DL) es una rama del aprendizaje automático, que se basa en redes neuronales artificiales. Las técnicas de DL son específicamente útiles para determinar patrones en grandes datos no estructurados. Es altamente beneficioso para evaluar daños durante un accidente, identificar anomalías en la facturación, etc. que eventualmente pueden ayudar en la detección de fraudes y mejores experiencias de los clientes.
La industria de seguros puede aprovechar la tecnología de aprendizaje profundo para mejorar el servicio, la automatización y la escala de las operaciones.
Por lo general, las aseguradoras analizan una propiedad solo una vez antes de cotizar una prima de seguro. Sin embargo, un cliente puede remodelar la propiedad, por ejemplo, instalar una piscina.
En tales casos, las aseguradoras pueden modificar proactivamente la cobertura del seguro con la ayuda de la tecnología de aprendizaje profundo. De hecho, con la tecnología de DL, las aseguradoras pueden ayudar a sus clientes con mantenimiento predictivo, análisis de fallas y apoyo en tiempo real.
Por ejemplo, El Nodo proporciona suscripción para propiedades multifamiliares. Permite a los usuarios analizar el alquiler histórico, los datos de concesión y los valores de mercado. Estas herramientas basadas en datos también son de gran ayuda para las aseguradoras.
Las aseguradoras están buscando diferentes formas de mejorar la experiencia del cliente. El Aprendizaje Profundo puede mejorar vívidamente las experiencias de interacción en diferentes puntos de contacto con el cliente. Tomemos, por ejemplo, el alcance de marketing. A través de recomendaciones personalizadas y estrategias de remarketing dinámico, las aseguradoras pueden lograr mejores conversiones. McKinsey afirma que la personalización puede reducir gastos de adquisición del cliente en hasta el 50%.
En el núcleo de estas estrategias se encuentra la tecnología de aprendizaje profundo. La tecnología DL puede hacer clasificaciones lógicas de datos no estructurados a través de un aprendizaje no supervisado. Ya hemos visto recomendaciones de productos basadas en nuestras propias preferencias, patrones de navegación / búsqueda e intereses de los compañeros. Lo mismo se aplica a la industria de los seguros, especialmente cuando las aseguradoras buscan ganancias a través de productos de seguros de tamaño reducido y bajo demanda.
El análisis y la evaluación actuariales son procesos que requieren mucho tiempo y son propensos a errores. Las aseguradoras pueden mejorar considerablemente los precios de las pólizas a través del razonamiento automatizado. Las técnicas de aprendizaje profundo combinan estadísticas, finanzas, negocios y razonamiento basado en el caso y pueden asistir a actuarios en la mejor evaluación de riesgos . Informes de Accenture: las aseguradoras están aprovechando el aprendizaje automático para la suscripción de seguros generales (56%) y de vida (39%).
Solo en Noruega en 2019, hubo 827 casos de fraude probados, que podrían haber causado una pérdida de más de € 11 millones a las aseguradoras.
El fraude de seguros generalmente ocurre en forma de reclamaciones . Un reclamante puede falsificar la identidad, duplicar reclamos, exagerar los costos de reparación y presentar recibos y facturas médicas falsas. Principalmente debido a fuentes de información desconectadas, las aseguradoras se caen de la víctima con actividades fraudulentas de clientes. Ahora, aquí está el desafío. ¿Cómo unificar diferentes fuentes de datos, que, hasta la fecha, incluyen recibos autónomos y documentos escaneados manualmente?
Aprendizaje Profundo puede ayudar en la detección de fraudes al:
El aprendizaje profundo incorpora beneficios dobles para las aseguradoras en términos de reclamos. Uno: con un ecosistema de información conectado, ayuda a las aseguradoras con una liquidación de reclamos más rápida (por lo tanto, la experiencia del cliente también). Dos, los modelos predictivos de aprendizaje profundo pueden equipar a las aseguradoras con una mejor comprensión del costo de las reclamaciones.
Por ejemplo, Tokio Marine, el mayor grupo de seguros de P&C (propiedad y daños) más grande de Japón, utiliza un sistema de procesamiento de documentos basado en la nube para procesar reclamaciones manuscritas desde el momento de la primera intimidación. Muchas aseguradoras esperan sistemas de procesamiento de reclamos de extremo a extremo con aprendizaje profundo y otras capacidades de IA.
Hoy en día, la tecnología de Aprendizaje Profundo tiene capaz de imitar el cerebro de un bebé. La investigación está en el desarrollo de nuevas arquitecturas de redes neuronales (por ejemplo Siamese Network, el modelo GPT-2 de OpenAI, etc.) que serán capaces de realizar funcionalidades complejas de un cerebro humano maduro. La tecnología de Aprendizaje Profundo, en un futuro próximo, liderará el desarrollo de sistemas de seguros basados en la cognición.
También, Lea: ¡La aseguradora cognitiva en la nube es la siguiente!
Knowledge thats worth delivered in your inbox
AI code assistants are revolutionizing software development, with Gartner predicting that 75% of enterprise software engineers will use these tools by 2028, up from less than 10% in early 2023. This rapid adoption reflects the potential of AI to enhance coding efficiency and productivity, but also raises important questions about the maturity, benefits, and challenges of these emerging technologies.
The evolution of code assistance has been rapid and transformative, progressing from simple autocomplete features to sophisticated AI-powered tools. GitHub Copilot, launched in 2021, marked a significant milestone by leveraging OpenAI’s Codex to generate entire code snippets 1. Amazon Q, introduced in 2023, further advanced the field with its deep integration into AWS services and impressive code acceptance rates of up to 50%. GPT (Generative Pre-trained Transformer) models have been instrumental in this evolution, with GPT-3 and its successors enabling more context-aware and nuanced code suggestions.
These advancements have not only increased coding efficiency but also democratized software development, making it more accessible to novice programmers and non-professionals alike.
The landscape of AI code assistants is rapidly evolving, with adoption rates and performance metrics showcasing their growing maturity. Here’s a tabular comparison of some popular AI coding tools, including Amazon Q:
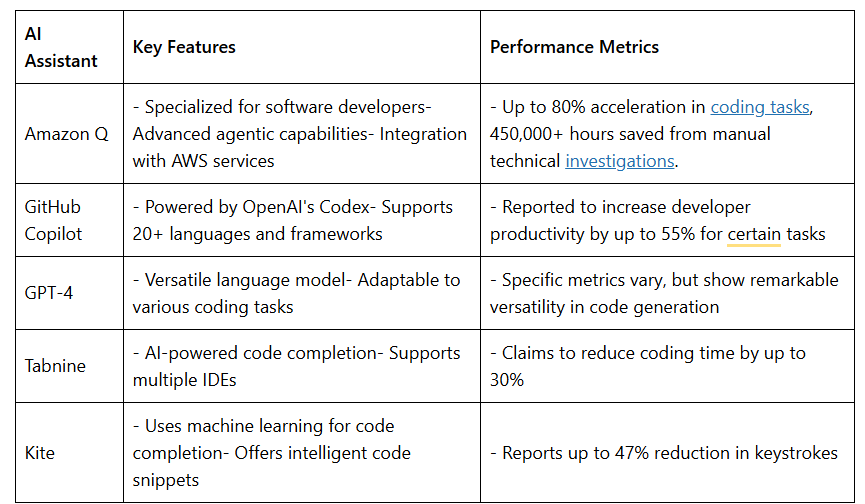
Amazon Q stands out with its specialized capabilities for software developers and deep integration with AWS services. It offers a range of features designed to streamline development processes:
The tool’s impact is evident in its adoption and performance metrics. For instance, Amazon Q has helped save over 450,000 hours from manual technical investigations. Its integration with CloudWatch provides valuable insights into developer usage patterns and areas for improvement.
As these AI assistants continue to mature, they are increasingly becoming integral to modern software development workflows. However, it’s important to note that while these tools offer significant benefits, they should be used judiciously, with developers maintaining a critical eye on the generated code and understanding its implications for overall project architecture and security.
AI code assistants are revolutionizing collaborative coding practices, offering real-time suggestions, conflict resolution, and personalized assistance to development teams. These tools integrate seamlessly with popular IDEs and version control systems, facilitating smoother teamwork and code quality improvements.
Key features of AI-enhanced collaborative coding:
Benefits for development teams:
While AI code assistants offer significant advantages, it’s crucial to maintain a balance between AI assistance and human expertise. Teams should establish guidelines for AI tool usage to ensure code quality, security, and maintainability.
Emerging trends in AI-powered collaborative coding:
As AI continues to evolve, collaborative coding tools are expected to become more sophisticated, further streamlining team workflows and fostering innovation in software development practices.
AI code assistants offer significant benefits but also present notable challenges. Here’s an overview of the advantages driving adoption and the critical downsides:
Core Advantages Driving Adoption:
| Industry | Potential Annual Value |
| Banking | $200 billion – $340 billion |
| Retail and CPG | $400 billion – $660 billion |
Critical Downsides and Risks:
While AI code assistants offer significant productivity gains and economic benefits, they also present challenges that need careful consideration. Developers and organizations must balance the advantages with the potential risks, ensuring responsible use of these powerful tools.
The future of AI code assistants is poised for significant growth and evolution, with technological advancements and changing developer attitudes shaping their trajectory towards potential ubiquity or obsolescence.
Technological Advancements on the Horizon:
Barriers:
Enablers:
As these trends unfold, the role of human developers is likely to shift towards higher-level problem-solving, creative design, and AI oversight. By 2025, it’s projected that over 70% of professional software developers will regularly collaborate with AI agents in their coding workflows1. However, the path to ubiquity will depend on addressing key challenges such as reliability, security, and maintaining a balance between AI assistance and human expertise.
The future outlook for AI code assistants is one of transformative potential, with the technology poised to become an integral part of the software development landscape. As these tools continue to evolve, they will likely reshape team structures, development methodologies, and the very nature of coding itself.
AI code assistants have irrevocably altered software development, delivering measurable productivity gains but introducing new technical and societal challenges. Current metrics suggest they are transitioning from novel aids to essential utilities—63% of enterprises now mandate their use. However, their ascendancy as the de facto standard hinges on addressing security flaws, mitigating cognitive erosion, and fostering equitable upskilling. For organizations, the optimal path lies in balanced integration: harnessing AI’s speed while preserving human ingenuity. As generative models evolve, developers who master this symbiosis will define the next epoch of software engineering.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.


