


Published on May 22, 2024
Updated on May 29, 2024
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(20)
Clean Tech(8)
Customer Journey(17)
Design(44)
Solar Industry(8)
User Experience(67)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(29)
Technology Modernization(8)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(38)
Insurtech(66)
Product Innovation(57)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(146)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(7)
Computer Vision(8)
Data Science(21)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(47)
Natural Language Processing(14)
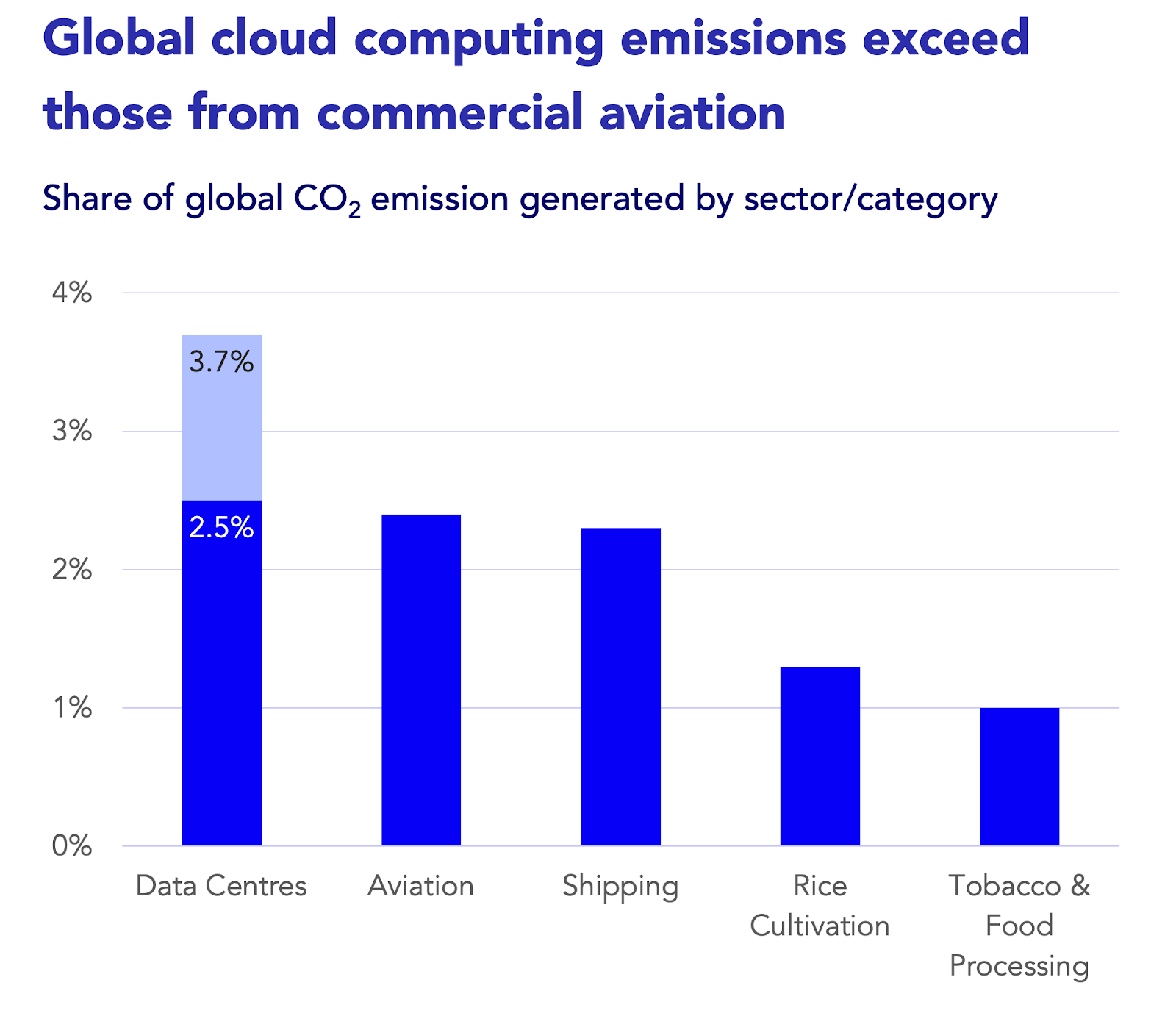
AI dazzles us with its feats, from chatbots understanding our queries to language models spinning creative tales. But have you pondered the colossal energy needed to fuel these technological marvels?
Research from the University of Massachusetts Amherst reveals that training a single behemoth like GPT-3, a titan among language models, emits carbon equivalent to 300,000 cars’ lifetime emissions. That’s akin to a medium-sized European town’s carbon output! And brace yourself: emissions from natural language processing doubled yearly till 2020, now rivaling the aviation industry’s impact. It’s as if countless planes continuously encircle the globe.
Yet, pulling the plug on AI isn’t an option. It’s entrenched in our lives, propelling innovation across sectors from healthcare to finance. The challenge? Balancing its ubiquity with sustainability.
The scale of energy consumption in the AI sector is staggering. According to a recent report by the International Energy Agency (IEA), global electricity consumption by AI data centers alone is projected to surpass 1,000 terawatt-hours annually by 2025, equivalent to the current electricity consumption of Japan and Germany combined. Such figures underscore the urgent need to address the environmental implications of AI’s rapid expansion.
AI: Here to Stay, but at What Expense? Indeed, the environmental cost is profound, necessitating concerted efforts from all stakeholders to reconcile AI’s benefits with its energy footprint.
Efforts span both hardware and software realms. Firms invest in energy-efficient hardware, like specialized chips and accelerators, and refine algorithms through compression and pruning, yielding environmental gains and cost savings.
Then there are the colossal data centers housing AI infrastructure. Leading cloud providers are pivoting to renewable energy sources and pioneering cooling systems, even exploring underwater data centers for natural cooling.

Governments worldwide are stepping into the fray, recognizing the urgent need for sustainable AI practices. Through a combination of regulations, incentives, and collaborative initiatives, policymakers are shaping a landscape where environmental consciousness is ingrained in technological innovation.
From establishing carbon emission targets specific to the AI sector to offering tax credits for companies adopting renewable energy solutions, governmental interventions are driving significant shifts towards sustainability. Additionally, partnerships between the public and private sectors are fostering innovative approaches to address the energy consumption dilemma without stifling technological advancement.
The responsibility falls not just on policymakers but also on AI developers and researchers to embed energy efficiency into the very fabric of AI design and implementation. By prioritizing sustainability metrics alongside performance benchmarks, the industry can pave the way for a greener future.
This involves not only optimizing algorithms and hardware but also cultivating a culture of environmental consciousness within AI development communities. Through knowledge-sharing, best practices, and collaborative research efforts, developers can collectively contribute to mitigating the environmental impact of AI technologies while maximizing their benefits.
Mantra Labs, in partnership with Viteos, developed advanced machine learning algorithms to optimize brokerage selection for specific trades and expedite insights from historical profit and loss (P&L) data. Our AI-enabled solution utilizes regression, outlier detection, and feature selection models to analyze historical transactions, trades, and financial data. It empowers Viteos’ users to efficiently identify the lowest-commission broker for their trades while ensuring rapid and accurate data insights. Our approach offers flexibility across diverse datasets and optimizes memory utilization, enhancing scalability and efficiency. To read the case study, click here.
AI’s future is luminous, but it must be energy-efficient. With collaborative efforts spanning tech firms, developers, policymakers, and users, we can safeguard the planet while advancing technological frontiers.
By embracing energy-smart practices and renewable energy, we can unlock AI’s potential while minimizing ecological fallout. The moment for action is now, and each stakeholder plays a pivotal role in crafting a sustainable AI tomorrow.
Knowledge thats worth delivered in your inbox
In 1997, the world watched in awe as IBM’s Deep Blue, a machine designed to play chess, defeated world champion Garry Kasparov. This moment wasn’t just a milestone for technology; it was a profound demonstration of data’s potential. Deep Blue analyzed millions of structured moves to anticipate outcomes. But imagine if it had access to unstructured data—Kasparov’s interviews, emotions, and instinctive reactions. Would the game have unfolded differently?
This historic clash mirrors today’s challenge in data architectures: leveraging structured, unstructured, and hybrid data systems to stay ahead. Let’s explore the nuances between Data Warehouses, Data Lakes, and Data Lakehouses—and uncover how they empower organizations to make game-changing decisions.
Deep Blue’s triumph was rooted in its ability to process structured data—moves on the chessboard, sequences of play, and pre-defined rules. Similarly, in the business world, structured data forms the backbone of decision-making. Customer transaction histories, financial ledgers, and inventory records are the “chess moves” of enterprises, neatly organized into rows and columns, ready for analysis. But as businesses grew, so did their need for a system that could not only store this structured data but also transform it into actionable insights efficiently. This need birthed the data warehouse.
Data warehouses act as the strategic command centers for enterprises. By employing a schema-on-write approach, they ensure data is cleaned, validated, and formatted before storage. This guarantees high accuracy and consistency, making them indispensable for industries like finance and healthcare. For instance, global banks rely on data warehouses to calculate real-time risk assessments or detect fraud—a necessity when billions of transactions are processed daily, tools like Amazon Redshift, Snowflake Data Warehouse, and Azure Data Warehouse are vital. Similarly, hospitals use them to streamline patient care by integrating records, billing, and treatment plans into unified dashboards.
The impact is evident: according to a report by Global Market Insights, the global data warehouse market is projected to reach $30.4 billion by 2025, driven by the growing demand for business intelligence and real-time analytics. Yet, much like Deep Blue’s limitations in analyzing Kasparov’s emotional state, data warehouses face challenges when encountering data that doesn’t fit neatly into predefined schemas.
The question remains—what happens when businesses need to explore data outside these structured confines? The next evolution takes us to the flexible and expansive realm of data lakes, designed to embrace unstructured chaos.
While structured data lays the foundation for traditional analytics, the modern business environment is far more complex, organizations today recognize the untapped potential in unstructured and semi-structured data. Social media conversations, customer reviews, IoT sensor feeds, audio recordings, and video content—these are the modern equivalents of Kasparov’s instinctive reactions and emotional expressions. They hold valuable insights but exist in forms that defy the rigid schemas of data warehouses.
Data lake is the system designed to embrace this chaos. Unlike warehouses, which demand structure upfront, data lakes operate on a schema-on-read approach, storing raw data in its native format until it’s needed for analysis. This flexibility makes data lakes ideal for capturing unstructured and semi-structured information. For example, Netflix uses data lakes to ingest billions of daily streaming logs, combining semi-structured metadata with unstructured viewing behaviors to deliver hyper-personalized recommendations. Similarly, Tesla stores vast amounts of raw sensor data from its autonomous vehicles in data lakes to train machine learning models.
However, this openness comes with challenges. Without proper governance, data lakes risk devolving into “data swamps,” where valuable insights are buried under poorly cataloged, duplicated, or irrelevant information. Forrester analysts estimate that 60%-73% of enterprise data goes unused for analytics, highlighting the governance gap in traditional lake implementations.
This gap gave rise to the data lakehouse, a hybrid approach that marries the flexibility of data lakes with the structure and governance of warehouses. The lakehouse supports both structured and unstructured data, enabling real-time querying for business intelligence (BI) while also accommodating AI/ML workloads. Tools like Databricks Lakehouse and Snowflake Lakehouse integrate features like ACID transactions and unified metadata layers, ensuring data remains clean, compliant, and accessible.
Retailers, for instance, use lakehouses to analyze customer behavior in real time while simultaneously training AI models for predictive recommendations. Streaming services like Disney+ integrate structured subscriber data with unstructured viewing habits, enhancing personalization and engagement. In manufacturing, lakehouses process vast IoT sensor data alongside operational records, predicting maintenance needs and reducing downtime. According to a report by Databricks, organizations implementing lakehouse architectures have achieved up to 40% cost reductions and accelerated insights, proving their value as a future-ready data solution.
As businesses navigate this evolving data ecosystem, the choice between these architectures depends on their unique needs. Below is a comparison table highlighting the key attributes of data warehouses, data lakes, and data lakehouses:
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
| Data Type | Structured | Structured, Semi-Structured, Unstructured | Both |
| Schema Approach | Schema-on-Write | Schema-on-Read | Both |
| Query Performance | Optimized for BI | Slower; requires specialized tools | High performance for both BI and AI |
| Accessibility | Easy for analysts with SQL tools | Requires technical expertise | Accessible to both analysts and data scientists |
| Cost Efficiency | High | Low | Moderate |
| Scalability | Limited | High | High |
| Governance | Strong | Weak | Strong |
| Use Cases | BI, Compliance | AI/ML, Data Exploration | Real-Time Analytics, Unified Workloads |
| Best Fit For | Finance, Healthcare | Media, IoT, Research | Retail, E-commerce, Multi-Industry |
The interplay between data warehouses, data lakes, and data lakehouses is a tale of adaptation and convergence. Just as IBM’s Deep Blue showcased the power of structured data but left questions about unstructured insights, businesses today must decide how to harness the vast potential of their data. From tools like Azure Data Lake, Amazon Redshift, and Snowflake Data Warehouse to advanced platforms like Databricks Lakehouse, the possibilities are limitless.
Ultimately, the path forward depends on an organization’s specific goals—whether optimizing BI, exploring AI/ML, or achieving unified analytics. The synergy of data engineering, data analytics, and database activity monitoring ensures that insights are not just generated but are actionable. To accelerate AI transformation journeys for evolving organizations, leveraging cutting-edge platforms like Snowflake combined with deep expertise is crucial.
At Mantra Labs, we specialize in crafting tailored data science and engineering solutions that empower businesses to achieve their analytics goals. Our experience with platforms like Snowflake and our deep domain expertise makes us the ideal partner for driving data-driven innovation and unlocking the next wave of growth for your enterprise.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
