


Published on Jul 25, 2019
Updated on Apr 3, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(5)
Manufacturing(3)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(38)
Insurtech(66)
Product Innovation(58)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(153)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(23)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
The machines are learning. Slowly, sure, but they are learning and we (humans) are the ones teaching them. We tell the machines how they should learn through the algorithms we write, and then feed them an enormous amount of data, so that it trains endlessly. Data labeling (the process of augmenting unlabelled data with meaningful and informative tags), is a necessary part of machine learning and sadly there’s a simple reason behind the use of a lower-wage workforce to train ML (Machine Learning) models — you only pay them half as much. The market for AI data preparation is projected to leap from $500M in 2018 to $1.2B by 2023.
Data is the only real fodder for any type of AI system. The more it trains on large amounts of ‘good data’, the faster it learns. Behind every piece of machine learning code intended to solve real issues, is a network of digital construction workers bearing the burden of building the foundation for AI — preparing data. For example, AI systems are trained to recognize objects. Data Labelers upload, categorize and cluster millions of images — just about everything from people, animals, buildings, plants, cars, signs, shapes, and things. In doing so, you now have an AI system that can begin to recognize these objects in the real world.
Again, for example, an algorithm meant to classify images of animals uses a large volume of images of different types of animals (dogs, leopards, giraffes, zebras, etc.) to train the model. These images will be labeled and classified for the model to work. A data labeler typically performs this essential function. It annotates the images with the right answers and transforms the dataset into a format suitable for machine/ deep learning.

Data Enrichment for Training ML Models
The real underlying aspect to machine intelligence is ‘the human’ in the AI loop — and it isn’t going away anytime soon either. Functions like data labeling are vital for AI quality control. Big Tech firms readily outsource these tasks to parts of the world where the minimum wage is significantly lower in order to meet extremely ambitious goals within budget. Data preparation and engineering tasks represent over 80% of the time consumed in most AI and machine learning projects.
For instance, small data labeling companies in Kenya (and others spread across Africa) are working with large American & European firms to help them classify and organize millions of datasets. The task involves highlighting and labeling images of vehicles, traffic lights, landmarks, road signs and pedestrians captured by cameras fixed on autonomous vehicles so that these machines can become aware of the objects around them.

Bounding Boxes (tagging images for machine or deep learning models)

Image Segmentation (recognize objects of different shapes, sizes, and positions)
(source: clickworker)
Automation (the precursor to true AI) has put low-skilled jobs at supposed “extinction-level” risk for several decades now, as self-driving cars, rules-based process bots, and speech recognition will continue to exacerbate this trend. In reality, the advances of digital industrialism are not new, neither is the elimination or replacement of low-skill jobs with newer low-skill jobs.
Sebenz.ai, a South African AI firm, is trying to create job opportunities for people throughout Africa leveraging the growing demand locally for data labelers. They have produced a Machine Learning ‘labeling game’ that allows people to earn money on their phones by labeling training data for ML models. Using this innovative approach, Sebenz is able to create labeled-data with real-time responses almost in parallel to train these models accurately.
According to the firm, it takes 10,000 hours of audio to train a speech-to-text model. With 1 data labeler, it would take 65 months, but with 10,000 people it would be ready in a few hours. In return, the data labelers are compensated around $16 per day, (minimum wage in the African continent is only a paltry $3 per day), albeit affording them the opportunity to make a better living. Most of the people drawn to data labeling jobs are often unskilled workers and live below the poverty line.
According to a 2018 KPMG research report, 5% or more of the global workforce will be replaced by automation within the next 2 years.
When Silicon Valley first began importing ‘cleaned’ data in bulk at nearly a fraction of the price, then it would otherwise cost them in their own markets — it wasn’t initially received as the modest competitive advantage as it is today. However, looking ahead at the ‘future of work’ and the role of Big Tech in shaping the informal economy — the low skilled jobs fueling automation and AI will soon become automated themselves, creating newer jobs and roles for people en masse to move into, yet again.

Join our Webinar — AI for Data-driven Insurers: Challenges, Opportunities & the Way Forward hosted by our CEO, Parag Sharma as he addresses Insurance business leaders and decision-makers on April 14, 2020.
AI is shaping the future of enterprises and consumer-services in affordable and scalable ways. To learn more about how we can transform your AI journey, reach out to us at hello@mantralabsglobal.com.
Knowledge thats worth delivered in your inbox
AI code assistants are revolutionizing software development, with Gartner predicting that 75% of enterprise software engineers will use these tools by 2028, up from less than 10% in early 2023. This rapid adoption reflects the potential of AI to enhance coding efficiency and productivity, but also raises important questions about the maturity, benefits, and challenges of these emerging technologies.
The evolution of code assistance has been rapid and transformative, progressing from simple autocomplete features to sophisticated AI-powered tools. GitHub Copilot, launched in 2021, marked a significant milestone by leveraging OpenAI’s Codex to generate entire code snippets 1. Amazon Q, introduced in 2023, further advanced the field with its deep integration into AWS services and impressive code acceptance rates of up to 50%. GPT (Generative Pre-trained Transformer) models have been instrumental in this evolution, with GPT-3 and its successors enabling more context-aware and nuanced code suggestions.
These advancements have not only increased coding efficiency but also democratized software development, making it more accessible to novice programmers and non-professionals alike.
The landscape of AI code assistants is rapidly evolving, with adoption rates and performance metrics showcasing their growing maturity. Here’s a tabular comparison of some popular AI coding tools, including Amazon Q:
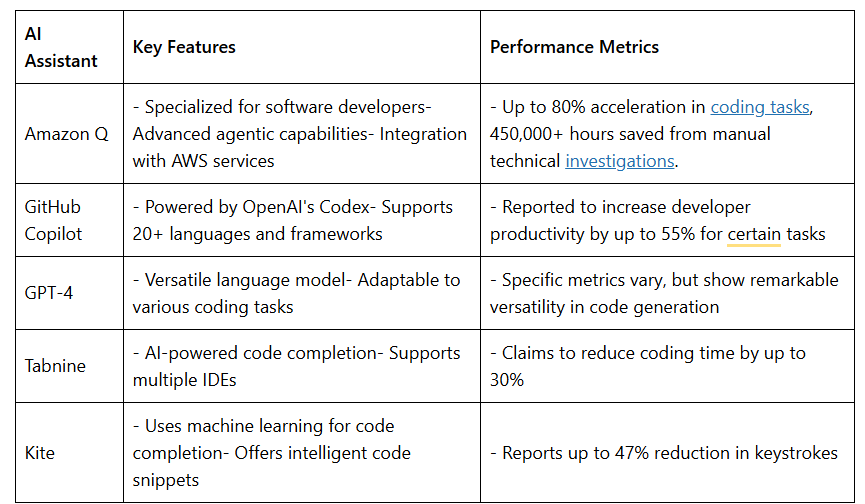
Amazon Q stands out with its specialized capabilities for software developers and deep integration with AWS services. It offers a range of features designed to streamline development processes:
The tool’s impact is evident in its adoption and performance metrics. For instance, Amazon Q has helped save over 450,000 hours from manual technical investigations. Its integration with CloudWatch provides valuable insights into developer usage patterns and areas for improvement.
As these AI assistants continue to mature, they are increasingly becoming integral to modern software development workflows. However, it’s important to note that while these tools offer significant benefits, they should be used judiciously, with developers maintaining a critical eye on the generated code and understanding its implications for overall project architecture and security.
AI code assistants are revolutionizing collaborative coding practices, offering real-time suggestions, conflict resolution, and personalized assistance to development teams. These tools integrate seamlessly with popular IDEs and version control systems, facilitating smoother teamwork and code quality improvements.
Key features of AI-enhanced collaborative coding:
Benefits for development teams:
While AI code assistants offer significant advantages, it’s crucial to maintain a balance between AI assistance and human expertise. Teams should establish guidelines for AI tool usage to ensure code quality, security, and maintainability.
Emerging trends in AI-powered collaborative coding:
As AI continues to evolve, collaborative coding tools are expected to become more sophisticated, further streamlining team workflows and fostering innovation in software development practices.
AI code assistants offer significant benefits but also present notable challenges. Here’s an overview of the advantages driving adoption and the critical downsides:
Core Advantages Driving Adoption:
| Industry | Potential Annual Value |
| Banking | $200 billion – $340 billion |
| Retail and CPG | $400 billion – $660 billion |
Critical Downsides and Risks:
While AI code assistants offer significant productivity gains and economic benefits, they also present challenges that need careful consideration. Developers and organizations must balance the advantages with the potential risks, ensuring responsible use of these powerful tools.
The future of AI code assistants is poised for significant growth and evolution, with technological advancements and changing developer attitudes shaping their trajectory towards potential ubiquity or obsolescence.
Technological Advancements on the Horizon:
Barriers:
Enablers:
As these trends unfold, the role of human developers is likely to shift towards higher-level problem-solving, creative design, and AI oversight. By 2025, it’s projected that over 70% of professional software developers will regularly collaborate with AI agents in their coding workflows1. However, the path to ubiquity will depend on addressing key challenges such as reliability, security, and maintaining a balance between AI assistance and human expertise.
The future outlook for AI code assistants is one of transformative potential, with the technology poised to become an integral part of the software development landscape. As these tools continue to evolve, they will likely reshape team structures, development methodologies, and the very nature of coding itself.
AI code assistants have irrevocably altered software development, delivering measurable productivity gains but introducing new technical and societal challenges. Current metrics suggest they are transitioning from novel aids to essential utilities—63% of enterprises now mandate their use. However, their ascendancy as the de facto standard hinges on addressing security flaws, mitigating cognitive erosion, and fostering equitable upskilling. For organizations, the optimal path lies in balanced integration: harnessing AI’s speed while preserving human ingenuity. As generative models evolve, developers who master this symbiosis will define the next epoch of software engineering.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.


