


6 minutes, 18 seconds read
Published on Mar 4, 2020
Updated on Apr 24, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.
Automated compliance and control for global regulations.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(5)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(41)
Insurtech(67)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(25)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(154)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(24)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
To scale-up the employee and customer satisfaction levels, enterprises frequently roll features to their software and applications. For instance, ING — the Dutch multinational financial services company releases features to its web and mobile sites every three weeks and has reported impressive improvement in its customer satisfaction scores.
New releases and enhancements are integral to agile businesses. But with these, comes the requirement to ensure a seamless experience for the user while using the application.
Whenever there is a change in code across multiple releases or multiple builds for the enhancement or bug fix and due to these changes there might be an Impact Area. Testing these Impact Areas is known as Regression Testing.
Regression testing is a combination of all the functional, integration and system test cases. Here, testers pick the test cases from the Test Case Repository. Organizations use regression testing in the following ways-
Mainly, regression testing requires 3 things-
There are 3 main types of regression testing in agile:
This testing method tests the code as a single unit.
It involves testing the Impacted Areas of the software due to new feature releases or major enhancement to the existing features.
It is a comprehensive testing method that involves testing the changed unit as well as independent old features of the application.
Regression testing is also done at the product/application development stage.
Regression testing at release level corresponds to testing during the second release of an application.
Regression testing at build level corresponds to testing during the second build of the upcoming release.
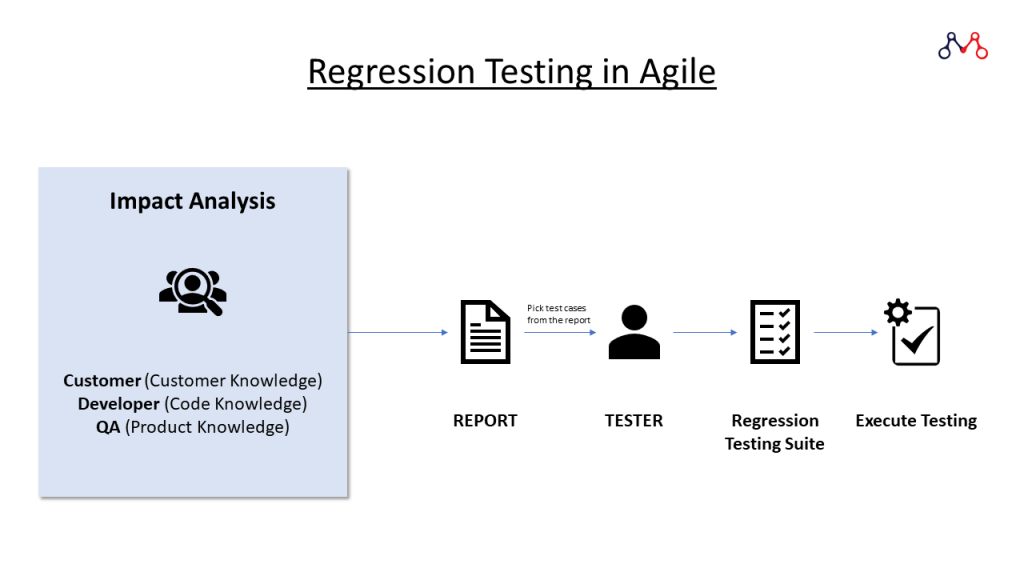
The main challenges of Regression Testing is to Identify the Impact Area.
This is where Test Automation comes into place.
Read more: Everything about Test Automation as a Service (TAAAS)
It may look like Test Automation might replace manual QA Engineers, but that’s not the case. Regression testing in agile still requires QA in the following instances.
In agile, enterprises need testing with each sprint. On the other hand, testers need to ensure that new changes do not affect existing functionalities of the product/application. Therefore, agile combines both regression testing and test automation to accelerate the product’s time-to-market.
If you’re looking for Testing Services for your Enterprises, please feel free to drop us a word at hello@mantralabsglobal.com. You can also check out our Testing Services.
Quality is never an accident; it is always the result of intelligent effort.
John Ruskin
About the author: Ankur Vishwakarma is a Software Engineer — QA at Mantra Labs Pvt Ltd. He is integral to the organization’s testing services. Apart from writing test scripts, you can find Ankur hauling on his Enfield!
Regression testing is done to ensure that any new feature or enhancement in the existing application runs smoothly and any change in code does not impact the functionality of the product.
UAT corresponds to User Acceptance Testing. It is the last phase of the software testing process. Regression Testing is not a part of UAT as it is done on product/application features and updates.
Agile implies an iterative development methodology. Agile testing corresponds to a continuous process rather than sequential. In this method, features are tested as they’re developed.
Functional testing ensures that all the functionalities of an application are working fine. It is done before the product release. Regression testing ensures that new features or enhancements are working correctly after the build is released.
Related:
Knowledge thats worth delivered in your inbox
Smart Manufacturing starts with real-time visibility.
Manufacturing companies today generate data by the second through sensors, machines, ERP systems, and MES platforms. But without real-time insights, even the most advanced production lines are essentially flying blind.
Manufacturers are implementing real-time dashboards that serve as control towers for their daily operations, enabling them to shift from reactive to proactive decision-making. These tools are essential to the evolution of Smart Manufacturing, where connected systems, automation, and intelligent analytics come together to drive measurable impact.
Data is available, but what’s missing is timely action.
For many plant leaders and COOs, one challenge persists: operational data is dispersed throughout systems, delayed, or hidden in spreadsheets. And this delay turns into a liability.
Real-time dashboards help uncover critical answers:
By converting raw inputs into real-time manufacturing analytics, dashboards make operational intelligence accessible to operators, supervisors, and leadership alike, enabling teams to anticipate problems rather than react to them.
Line performance and downtime trends
Track OEE in real time and identify underperforming lines.
Predictive maintenance alerts
Utilize historical and sensor data to identify potential part failures in advance.
Inventory heat maps & reorder thresholds
Anticipate stockouts or overstocks based on dynamic reorder points.
Quality metrics linked to operator actions
Isolate shifts or procedures correlated with spikes in defects or rework.
These insights allow production teams to drive day-to-day operations in line with Smart Manufacturing principles.
Role-based dashboards
Dashboards can be configured for machine operators, shift supervisors, and plant managers, each with a tailored view of KPIs.
Embedded alerts and nudges
Real-time prompts, like “Line 4 below efficiency threshold for 15+ minutes,” reduce response times and minimize disruptions.
Cross-functional drill-downs
Teams can identify root causes more quickly because users can move from plant-wide overviews to detailed machine-level data in seconds.
Data lakehouse integration
Unified access to ERP, MES, IoT sensor, and QA systems—ensuring reliable and timely manufacturing analytics.
ETL pipelines
Real-time data ingestion from high-frequency sources with minimal latency.
Visualization tools
Custom builds using Power BI, or customized solutions designed for frontline usability and operational impact.
Mantra Labs partnered with a North American die-casting manufacturer to unify its operational data into a real-time dashboard. Fragmented data, manual reporting, delayed pricing decisions, and inconsistent data quality hindered operational efficiency and strategic decision-making.
As this case shows, real-time dashboards are not just operational tools—they’re strategic enablers.
(Learn More: Powering the Future of Metal Manufacturing with Data Engineering)
| Aspect | What You Should Know |
| 1. Why Static Reports Fall Short | Delayed insights after issues occur Disconnected systems (ERP, MES, sensors) No real-time alerts or embedded decision logic |
| 2. What Real-Time Dashboards Enable | Track OEE and downtime in real-time Predictive maintenance using sensor data Dynamic inventory heat maps Quality linked to operators |
| 3. Dashboards That Drive Action | Role-based views (operator to CEO) Embedded alerts like “Line 4 down for 15+ mins” Drilldowns from plant-level to machine-level |
| 4. What Powers These Dashboards | Unified Data Lakehouse (ERP + IoT + MES) Real-time ETL pipelines Power BI or custom dashboards built for frontline usability |
Smart Manufacturing dashboards aren’t just analytics tools—they’re productivity engines. Dashboards that deliver real-time insight empower frontline teams to make faster, better decisions—whether it’s adjusting production schedules, triggering preventive maintenance, or responding to inventory fluctuations.
Explore how Mantra Labs can help you unlock operations intelligence that’s actually usable.
Knowledge thats worth delivered in your inbox


Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
